MLOps Engines#
Work in Progress
This chapter is still being written & reviewed. Please do post links & discussion in the comments below, or open a pull request!
Some ideas:
7 Frameworks for Serving LLMs “comprehensive guide & detailed comparison”
Python Bindings and More
PyTorch Toolchain – From C/C++ to Python
Apache TVM
This chapter focuses on recent open-source MLOps engine developments – which are largely due to the current rise of LLMs. While MLOps typically focuses on model training, “LLMOps” focuses on fine-tuning. In production, both also require good inference engines.
Inference Engine |
Open-Source |
GPU optimisations |
Ease of use |
|---|---|---|---|
🟢 Yes |
Dynamic Batching, Tensor Parallelism, Model concurrency |
🔴 Difficult |
|
🟢 Yes |
Continuous Batching, Tensor Parallelism, Flash Attention |
🟢 Easy |
|
🟢 Yes |
Continuous Batching, Tensor Parallelism, Paged Attention |
🟢 Easy |
|
🟢 Yes |
None |
🟢 Easy |
|
🔴 No |
N/A |
🟡 Moderate |
|
🟢 Yes |
🟢 Yes |
🟢 Easy |
Feedback
Is the table above outdated or missing an important model? Let us know in the comments below, or open a pull request!
Nvidia Triton Inference Server#
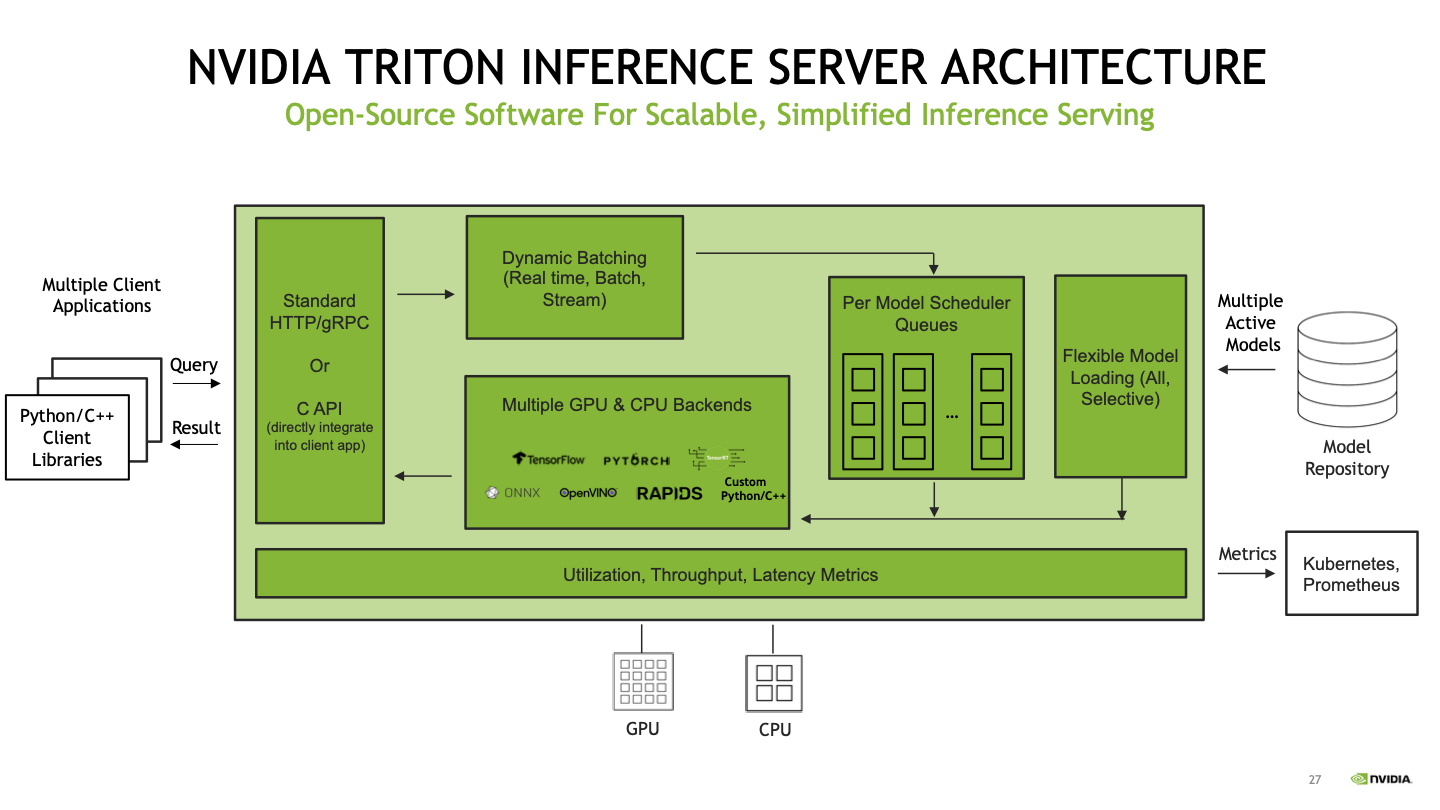
Fig. 61 Nvidia Triton Architecture#
This inference server offers support for multiple model formats such as PyTorch, TensorFlow, ONNX, TensorRT, etc. It uses GPUs efficiently to boost the performance of deep learning models.
Concurrent model execution: This allows multiple models to be executed on 1 or many GPUs in parallel. Multiple requests are routed to each model to execute the tasks in parallel
Dynamic Batching: Combines multiple inference requests into a batch to increase throughput. Requests in each batch can be processed in parallel instead of handling each request sequentially.
Pros:
High throughput, low latency for serving LLMs on a GPU
Supports multiple frameworks/backends
Production level performance
Works with non-LLM models such as image generation or speech to text
Cons:
Difficult to set up
Not compatible with many of the newer LLMs
Text Generation Inference#
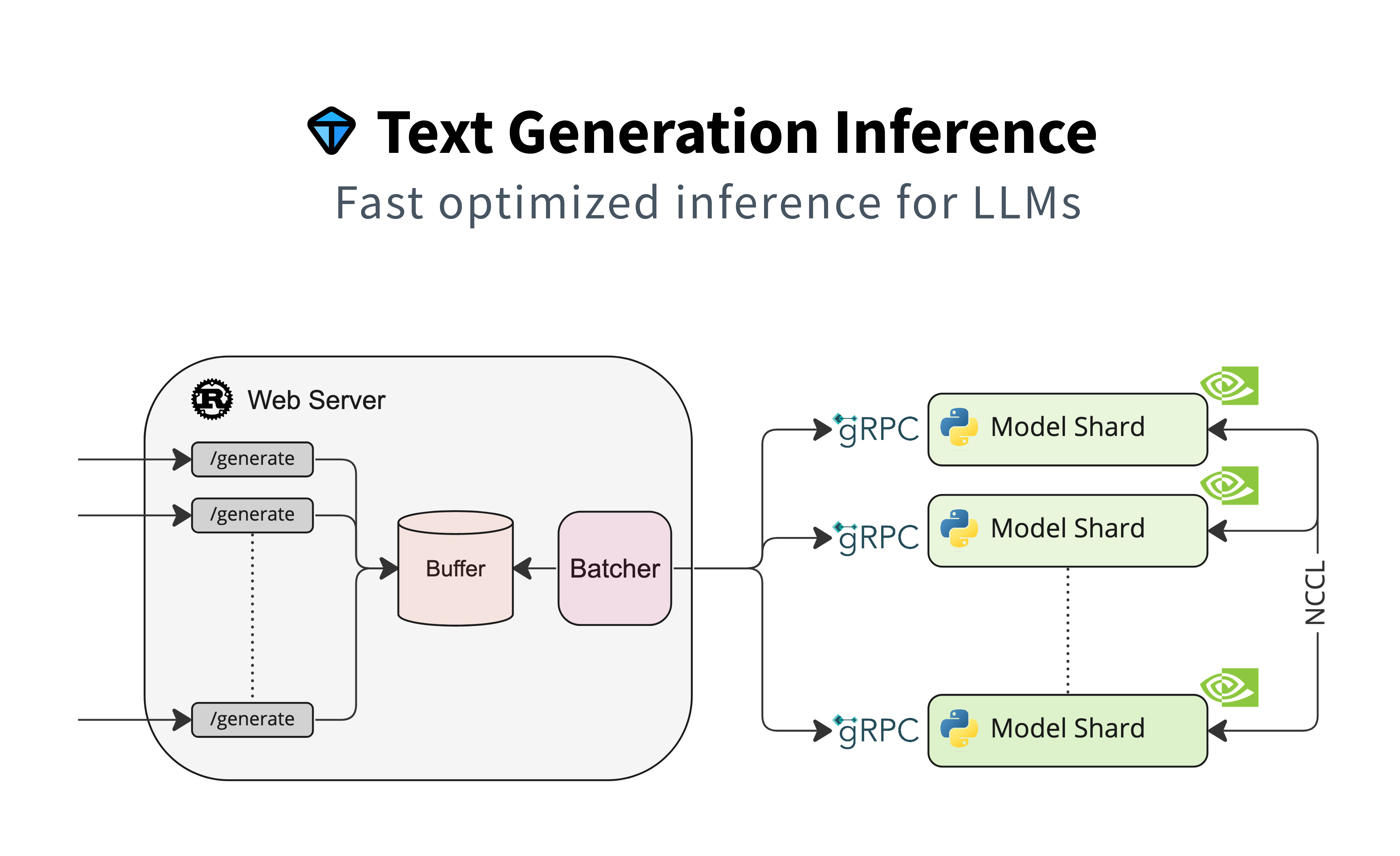
Compared to Triton, huggingface/text-generation-inference is easier to setup and supports most of the popular LLMs on Hugging Face.
Pros:
Supports newer models on Hugging Face
Easy setup via docker container
Production-ready
Cons:
Open-source license has restrictions on commercial usage
Only works with Hugging Face models
vLLM#
This is an open-source project created by researchers at Berkeley to improve the performance of LLM inferencing. vllm-project/vllm primarily optimises LLM throughput via methods like PagedAttention and Continuous Batching. The project is fairly new and there is ongoing development.
Pros:
Can be used commercially
Supports many popular Hugging Face models
Easy to setup
Cons:
Not all LLM models are supported
BentoML#
BentoML is a fairly popular tool used to deploy ML models into production. It has gained a lot of popularity by building simple wrappers that can convert any model into a REST API endpoint. Currently, BentoML does not support some of the GPU optimizations such as tensor parallelism. However, the main benefit BentoML provides is that it can serve a wide variety of models.
Pros:
Easy setup
Can be used commercially
Supports all models
Cons:
Lacks some GPU optimizations
Modular#
Modular is designed to be a high performance AI engine that boosts the performance of deep learning models. The secret is in their custom compiler and runtime environment that improves the inferencing of any model without the developer needing to make any code changes.
The Modular team has designed a new programming language, Mojo, which combines the Python friendly syntax with the performance of C. The purpose of Mojo is to address some of the shortcomings of Python from a performance standpoint while still being a part of the Python ecosystem. This is the programming language used internally to create the Modular AI engine’s kernels.
Pros:
Low latency/High throughput for inference
Compatible with Tensorflow and Pytorch models
Cons:
Not open-source
Not as simple to use compared to other engines on this list
This is not an exhaustive list of MLOps engines by any means. There are many other tools and frameworks developer use to deploy their ML models. There is ongoing development in both the open-source and private sectors to improve the performance of LLMs. It’s up to the community to test out different services to see which one works best for their use case.
LocalAI#
LocalAI from mudler/LocalAI (not to be confused with local.ai from louisgv/local.ai) is the free, Open Source alternative to OpenAI. LocalAI act as a drop-in replacement REST API that’s compatible with OpenAI API specifications for local inferencing. It can run LLMs (with various backend such as ggerganov/llama.cpp or vLLM), generate images, generate audio, transcribe audio, and can be self-hosted (on-prem) with consumer-grade hardware.
Pros:
support for functions (self-hosted OpenAI functions)
Cons:
binary version is harder to run and compile locally. mudler/LocalAI#1196.
high learning curve due to high degree of customisation
Challenges in Open Source#
MLOps solutions come in two flavours [144]:
Managed: a full pipeline (and support) is provided (for a price)
Self-hosted: various DIY stitched-together open-source components
Some companies (e.g. Hugging Face) push for open-source models & datasets, while others (e.g. OpenAI, Anthropic) do the opposite.
The main challenges with open-source MLOps are Maintenance, Performance, and Cost.

Fig. 63 Open-Source vs Closed-Source MLOps#
Maintenance#
Using open-source components, most setup & configuration must be done manually. This could mean finding & downloading models & datasets, setting up fine-tuning, performing evaluations, and Inference – all components held together by self-maintained bespoke “glue” code.
You are responsible for monitoring pipeline health & fixing issues quickly to avoid application downtime. This is particularly painful in the early stages of a project, when robustness and scalability are not yet implemented and there is much firefighting for developers to do.
Performance#
Performance could refer to:
output quality: e.g. accuracy – how close is a model’s output to ideal expectations (see Evaluation & Datasets), or
operational speed: e.g. throughput & latency – how much time it takes to complete a request (see also Hardware, which can play as large a role as software [145]).
By comparison, closed-source engines (e.g. Cohere) tend to give better baseline operational performance due to default-enabled inference optimisations [146].
Cost#
Self-maintained open-source solutions, if implemented well, can be extremely cheap both to setup and to run long term. However, many underestimate the amount of work required to make an open-source ecosystem work seamlessly.
For example, a single GPU node able to run a 36 GB open-source model can easily cost over $2,000 per month from a major cloud provider. Since the technology is still new, experimenting with & maintaining self-hosted infrastructure can be expensive. Conversely, closed-source pricing models often charge for usage (e.g. tokens) rather than infrastructure (e.g. ChatGPT costs around $0.002 for 1K tokens – enough for a page of text), making them much cheaper for small explorative tasks.
Inference#
Inference is one of the hot topics currently with LLMs in general. Large models like ChatGPT have very low latency and great performance but become more expensive with more usage.
On the flip side, open-source models like LLaMA-2 or Falcon have variants that are much smaller in size, yet it’s difficult to match the latency and throughput that ChatGPT provides, while still being cost efficient [147].
Models that are run using Hugging Face pipelines do not have the necessary optimisations to run in a production environment. The open-source LLM inferencing market is still evolving so currently there’s no silver bullet that can run any open-source LLM at blazing-fast speeds.
Here are a few reasons for why inferencing is slow:
Models are growing larger in size#
As models grow in size and neural networks become more complex it’s no surprise that it’s taking longer to get an output
Python as the choice of programming language for AI#
Python, is inherently slow compared to compiled languages like C++
The developer-friendly syntax and vast array of libraries have put Python in the spotlight, but when it comes to sheer performance it falls behind many other languages
To compensate for its performance many inferencing servers convert the Python code into an optimised module. For example, Nvidia’s Triton Inference Server can take a PyTorch model and compile it into TensorRT, which has a much higher performance than native PyTorch
Similarly, ggerganov/llama.cpp optimises the LLaMA inference code to run in raw C++. Using this optimisation, people can run a large language model on their laptops without a dedicated GPU.
Larger inputs#
Not only do LLMs have billions of parameters, but they perform millions of mathematical calculations for each inference
To do these massive calculations in a timely manner, GPUs are required to help speed up the process. GPUs have much more memory bandwidth and processing power compared to a CPU which is why they are in such high demand when it comes to running large language models.
Future#
Due to the challenge of running LLMs, enterprises will likely opt to use an inference server instead of containerising the model in-house. Optimising LLMs for inference requires a high level of expertise, which most companies many not have. Inference servers can help solve this problem by providing a simple and unified interface to deploy AI models at scale, while still being cost effective.
Another pattern that’s emerging is that models will move to the data instead of the data moving to the model. Currently, when calling the ChatGPT API data is sent to the model. Enterprises have worked very hard over the past decade to set up robust data infrastructure in the cloud. It makes a lot more sense to bring the model into the same cloud environment where the data is. This is where open-source models being cloud agnostic can have a huge advantage.
Before the word “MLOps” was coined, data scientists would manually train and run their models locally. At that time, data scientists were mostly experimenting with smaller statistical models. When they tried to bring this technology into production, they ran into many problems around data storage, data processing, model training, model deployment, and model monitoring. Companies started addressing these challenges and came up with a solution for running AI in production, hence “MLOps”.
Currently, we are in the experimental stage with LLMs. When companies try to use this technology in production, they will encounter a new set of challenges. Building solutions to address these challenges will build on the existing concept of MLOps.
Feedback
Missing something important? Let us know in the comments below, or open a pull request!