Model Formats#
As ML model applications increase, so too does the need for optimising the models for specific use-cases. To address performance-cost ratio and portability issues, there’s recently been a rise of competing model formats.
Feature |
|||
|---|---|---|---|
Ease of Use |
🟢 good |
🟡 moderate |
🟡 moderate |
Integration with Deep Learning Frameworks |
🟢 most |
🟡 growing |
🟡 growing |
Deployment Tools |
🟢 yes |
🔴 no |
🟢 yes |
Interoperability |
🟢 yes |
🔴 no |
🔴 no |
Inference Boost |
🟡 moderate |
🟢 good |
🟢 good |
Quantisation Support |
🟡 good |
🟢 good |
🟡 moderate |
Custom Layer Support |
🟢 yes |
🔴 limited |
🟢 yes |
Maintainer |
Feedback
Is the table above outdated or missing an important model? Let us know in the comments below, or open a pull request!
Repository |
Commit Rate |
Stars |
Contributors |
Issues |
Pull Requests |
|---|---|---|---|---|---|

























Based on the above stats, it looks like ggml is the most popular library currently, followed by onnx. Also one thing to note here is onnx repositories are around ~9x older compared to ggml repositories.
ONNX feels truly OSS, since it’s run by an OSS community, whereas both GGML and friends, TensorRT are run by Organisations (even though they are open source), and final decisions are made by a single (sometimes closed) entity which can finally affect on what kind of features that entity prefers or has biases towards even though both can have amazing communities at the same time.
ONNX#
ONNX (Open Neural Network Exchange) provides an open source format for AI models by defining an extensible computation graph model, as well as definitions of built-in operators and standard data types. It is widely supported and can be found in many frameworks, tools, and hardware enabling interoperability between different frameworks. ONNX is an intermediary representation of your model that lets you easily go from one environment to the next.
Features and Benefits#
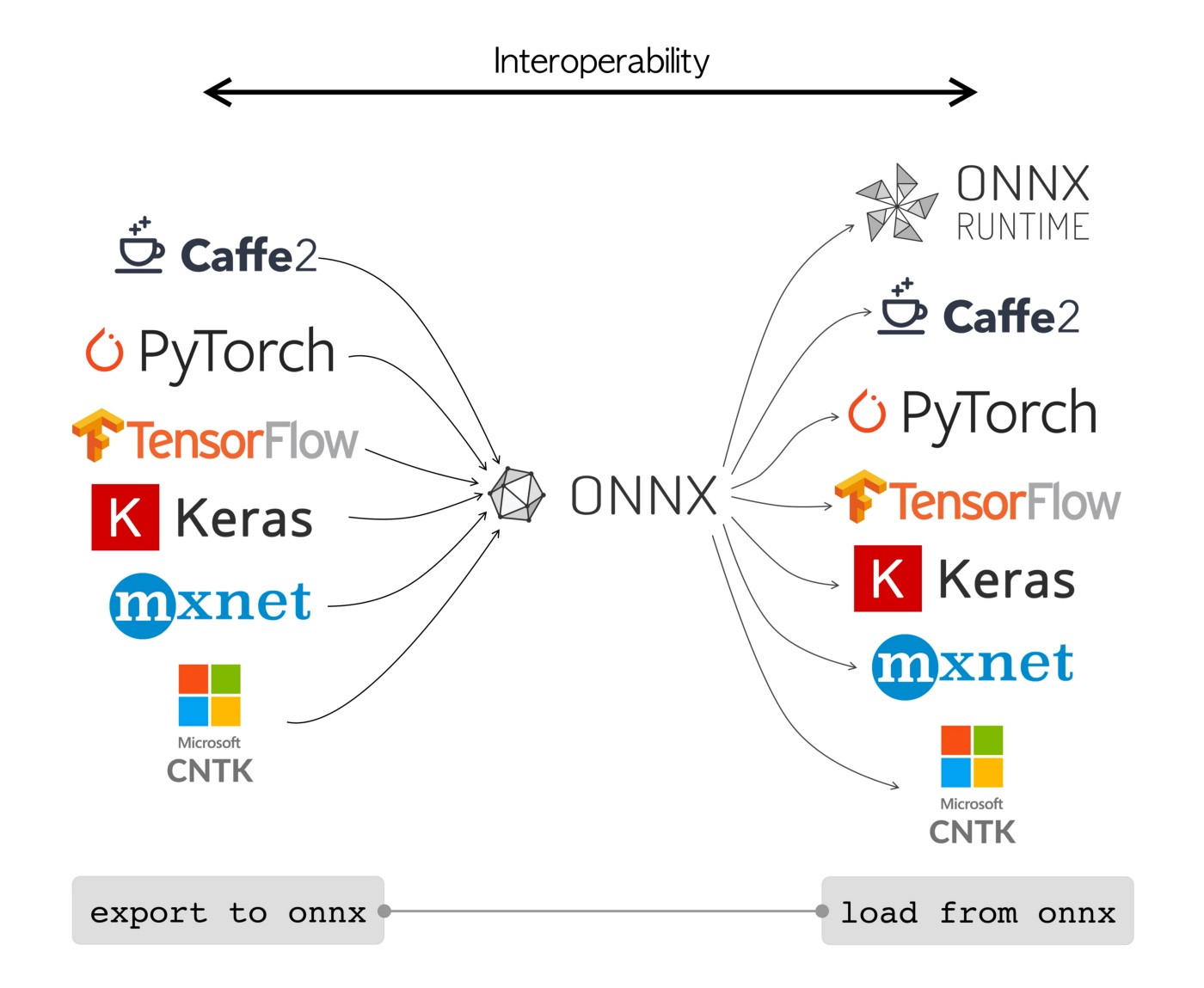
Fig. 58 https://cms-ml.github.io/documentation/inference/onnx.html#
Model Interoperability: ONNX bridges AI frameworks, allowing seamless model transfer between them, eliminating the need for complex conversions.
Computation Graph Model: ONNX’s core is a graph model, representing AI models as directed graphs with nodes for operations, offering flexibility.
Standardised Data Types: ONNX establishes standard data types, ensuring consistency when exchanging models, reducing data type issues.
Built-in Operators: ONNX boasts a rich library of operators for common AI tasks, enabling consistent computation across frameworks.
ONNX Ecosystem:
microsoft/onnxruntime A high-performance inference engine for cross-platform ONNX models.
onnx/onnxmltools Tools for ONNX model conversion and compatibility with frameworks like TensorFlow and PyTorch.
onnx/models A repository of pre-trained models converted to ONNX format for various tasks.
Hub: Helps sharing and collaborating on ONNX models within the community.
Usage#
Usability around ONNX is fairly developed and has lots of tooling support around it by the community, let’s see how we can directly export into onnx and make use of it.
Firstly the model needs to be converted to ONNX format using a relevant converter, for example if our model is created using Pytorch, for conversion we can use:
-
For custom operators support same exporter can be used.
Once exported we can load, manipulate, and run ONNX models. Let’s take a Python example:
To install the official onnx python package:
pip install onnx
To load, manipulate, and run ONNX models in your Python applications:
import onnx
# Load an ONNX model
model = onnx.load("your_awesome_model.onnx")
# Perform inference with the model
# (Specific inference code depends on your application and framework)
Support#
Many frameworks/tools are supported, with many examples/tutorials at onnx/tutorials.
It has support for Inference runtime binding APIs written in few programming languages (python, rust, js, java, C#).
ONNX model’s inference depends on the platform which runtime library supports, called Execution Provider. Currently there are few ranging from CPU based, GPU based, IoT/edge based and few others. A full list can be found here.
Onnxruntime has few example tools that can be used to quantize select ONNX models. Support is currenty based on operators in the model. Read more here.
Also there are few visualisation tools support like lutzroeder/Netron and more for models converted to ONNX format, highly recommended for debugging purposes.
Future#
Currently ONNX is part of LF AI Foundation, conducts regular Steering committee meetings and community meetups are held atleast once a year. Few notable presentations from this year’s meetup:
Analysis of Failures and Risks in Deep Learning Model Converters: A Case Study in the ONNX Ecosystem.
On-Device Training with ONNX Runtime: enabling training models on edge devices without the data ever leaving the device.
Checkout the full list here.
Limitations#
Onnx uses Opsets (Operator sets) number which changes with each ONNX package minor/major releases, new opsets usually introduces new operators. Proper opset needs to be used while creating the onnx model graph.
Also it currently doesn’t support 4-bit quantisation (microsoft/onnxruntime#14997).
There are lots of open issues (microsoft/onnxruntime#12880, #10303, #7233, #17116) where users are getting slower inference speed after converting their models to ONNX format when compared to base model format, it shows that conversion might not be easy for all models. On similar grounds an user comments 3 years ago here though it’s old, few points still seems relevant. The troubleshooting guide by ONNX runtime community can help with commonly faced issues.
Usage of Protobuf for storing/reading of ONNX models also seems to be causing few limitations which is discussed here.
There’s a detailed failure analysis (video, ppt) done by James C. Davis and Purvish Jajal on ONNX converters.
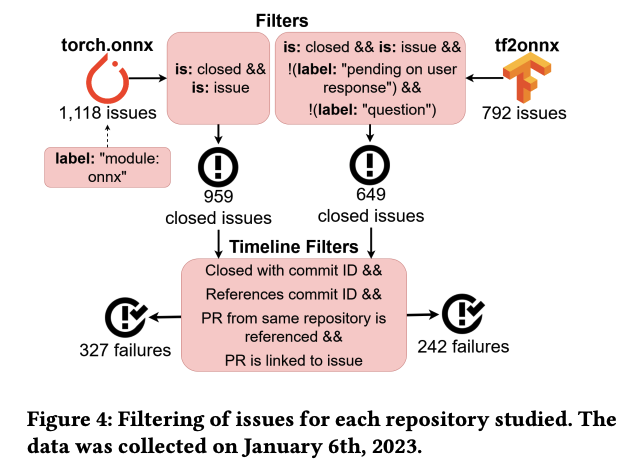
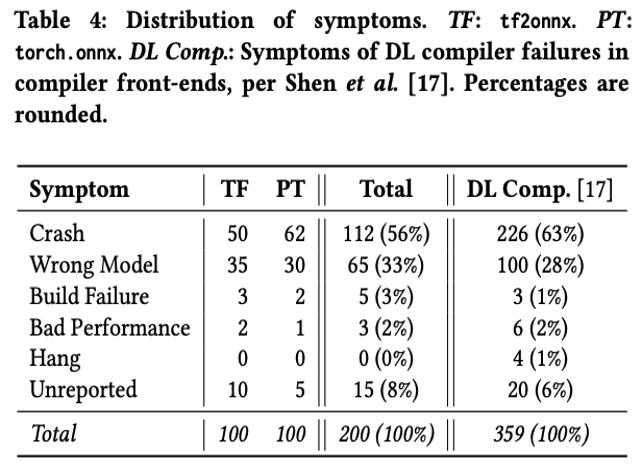
Fig. 59 Analysis of Failures and Risks in Deep Learning Model Converters [143]#
The top findings were:
Crash (56%) and Wrong Model (33%) are the most common symptoms
The most common failure causes are Incompatibility and Type problems, each making up ∼25% of causes
The majority of failures are located with the Node Conversion stage (74%), with a further 10% in the Graph optimisation stage (mostly from tf2onnx).
See also
webonnx/wonnx (GPU-based ONNX inference runtime in Rust)
GGML#
ggerganov/ggml is a tensor library for machine learning to enable large models and high performance on commodity hardware – the “GG” refers to the initials of its originator Georgi Gerganov. In addition to defining low-level machine learning primitives like a tensor type, GGML defines a binary format for distributing large language models (LLMs). llama.cpp and whisper.cpp are based on it.
Features and Benefits#
Written in C
16-bit float and integer quantisation support (e.g. 4-bit, 5-bit, 8-bit)
Automatic differentiation
Built-in optimisation algorithms (e.g. ADAM, L-BFGS)
Optimised for Apple Silicon, on x86 arch utilises AVX / AVX2 intrinsics
Web support via WebAssembly and WASM SIMD
No third-party dependencies
zero memory allocations during runtime
To know more, see their manifesto here
Usage#
Overall GGML is moderate in terms of usability given it’s a fairly new project and growing, but has lots of community support already.
Here’s an example inference of GPT-2 GGML:
git clone https://github.com/ggerganov/ggml
cd ggml
mkdir build && cd build
cmake ..
make -j4 gpt-2
# Run the GPT-2 small 117M model
../examples/gpt-2/download-ggml-model.sh 117M
./bin/gpt-2 -m models/gpt-2-117M/ggml-model.bin -p "This is an example"
Working#
For usage, the model should be saved in the particular GGML file format which consists binary-encoded data that has a particular format specifying what kind of data is present in the file, how it is represented, and the order in which it appears.
For a valid GGML file the following pieces of information should be present in order:
GGML version number: To support rapid development without sacrificing backwards-compatibility, GGML uses versioning to introduce improvements that may change the format of the encoding. The first value present in a valid GGML file is a “magic number” that indicates the GGML version that was used to encode the model. Here’s a GPT-2 conversion example where it’s getting written.
Components of LLMs:
Hyperparameters: These are parameters which configures the behaviour of models. Valid GGML files lists these values in the correct order, and each value represented using the correct data type. Here’s an example for GPT-2.
Vocabulary: These are all supported tokens for a model. Here’s an example for GPT-2.
Weights: These are also called parameters of the model. The total number of weights in a model are referred to as the “size” of that model. In GGML format a tensor consists of few components:
Name
4 element list representing number of dimensions in the tensor and their lengths
List of weights in the tensor
Let’s consider the following weights:
weight_1 = [[0.334, 0.21], [0.0, 0.149]] weight_2 = [0.123, 0.21, 0.31]
Then GGML representation would be:
{"weight_1", [2, 2, 1, 1], [0.334, 0.21, 0.0, 0.149]} {"weight_2", [3, 1, 1, 1], [0.123, 0.21, 0.31]}
For each weight representation the first list denotes dimensions and second list denotes weights. Dimensions list uses
1as a placeholder for unused dimensions.
Quantisation#
Quantisation is a process where high-precision foating point values are converted to low-precision values. This overall reduces the resources required to use the values in Tensor, making model easier to run on low resources. GGML uses a hacky version of quantisation and supports a number of different quantisation strategies (e.g. 4-bit, 5-bit, and 8-bit quantisation), each of which offers different trade-offs between efficiency and performance. Check out this amazing article by Merve for a quick walkthrough.
Support#
It’s most used projects include:
-
High-performance inference of OpenAI’s Whisper automatic speech recognition model The project provides a high-quality speech-to-text solution that runs on Mac, Windows, Linux, iOS, Android, Raspberry Pi, and Web. Used by rewind.ai
Optimised version for Apple Silicon is also available as a Swift package.
-
Inference of Meta’s LLaMA large language model
The project demonstrates efficient inference on Apple Silicon hardware and explores a variety of optimisation techniques and applications of LLMs
Inference and training of many open sourced models (StarCoder, Falcon, Replit, Bert, etc.) are already supported in GGML. Track the full list of updates here.
Tip
TheBloke currently has lots of LLM variants already converted to GGML format.
GPU based inference support for GGML format models discussion initiated few months back, examples started with MNIST CNN support, and showing other example of full GPU inference, showed on Apple Silicon using Metal, offloading layers to CPU and making use of GPU and CPU together.
Check llamacpp part of LangChain’s docs on how to use GPU or Metal for GGML models inference. Here’s an example from LangChain docs showing how to use GPU for GGML models inference.
Currently Speculative Decoding for sampling tokens is being implemented (ggerganov/llama.cpp#2926) for Code LLaMA inference as a POC, which as an example promises full float16 precision 34B Code LLAMA at >20 tokens/sec on M2 Ultra.
Future#
GGUF format#
There’s a new successor format to GGML named GGUF introduced by llama.cpp team on August 21st 2023. It has an extensible, future-proof format which stores more information about the model as metadata. It also includes significantly improved tokenisation code, including for the first time full support for special tokens. Promises to improve performance, especially with models that use new special tokens and implement custom prompt templates.
Some clients & libraries supporting GGUF include:
oobabooga/text-generation-webui – the most widely used web UI, with many features and powerful extensions
LostRuins/koboldcpp – a fully featured web UI, with full GPU accel across multiple platforms and GPU architectures. Especially good for story telling
ParisNeo/lollms-webui – a great web UI with many interesting and unique features, including a full model library for easy model selection
marella/ctransformers – a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server
abetlen/llama-cpp-python – a Python library with GPU accel, LangChain support, and OpenAI-compatible API server
huggingface/candle – a Rust ML framework with a focus on performance, including GPU support, and ease of use
LM Studio – an easy-to-use and powerful local GUI with GPU acceleration on both Windows (NVidia and AMD), and macOS
See also
For more info on GGUF, see ggerganov/llama.cpp#2398 and its spec.
Limitations#
Models are mostly quantised versions of actual models, taking slight hit from quality side if not much. Similar cases reported which is totally expected from a quantised model, some numbers can be found on this reddit discussion.
GGML is mostly focused on Large Language Models, but surely looking to expand.
See also
GGML: Large Language Models for Everyone – a description of the GGML format (by the maintainers of the
llmRust bindings for GGML)marella/ctransformers – Python bindings for GGML models
go-skynet/go-ggml-transformers.cpp – Golang bindings for GGML models
smspillaz/ggml-gobject – GObject-introspectable wrapper for using GGML on the GNOME platform
TensorRT#
TensorRT is an SDK for deep learning inference by NVIDIA, providing APIs and parsers to import trained models from all major deep learning frameworks which then generates optimised runtime engines deployable in diverse systems.
Features and Benefits#
TensorRT’s main capability comes under giving out high performance inference engines. Few notable features include:
Supports
float32,float16,int8,int32,uint8, andbooldata types.Plugin interface to extend TensorRT with operations not supported natively.
Works with both GPU (CUDA) and CPU.
Works with pre-quantised models.
Supports NVIDIA’s Deep Learning Accelerator (DLA).
Dynamic shapes for Input and Output.
TensorRT can also act as a provider when using onnxruntime delivering better inferencing performance on the same hardware compared to generic GPU acceleration by setting proper Execution Provider.
Usage#
Using NVIDIA’s TensorRT containers can ease up setup, given it’s known what version of TensorRT, CUDA toolkit (if required).
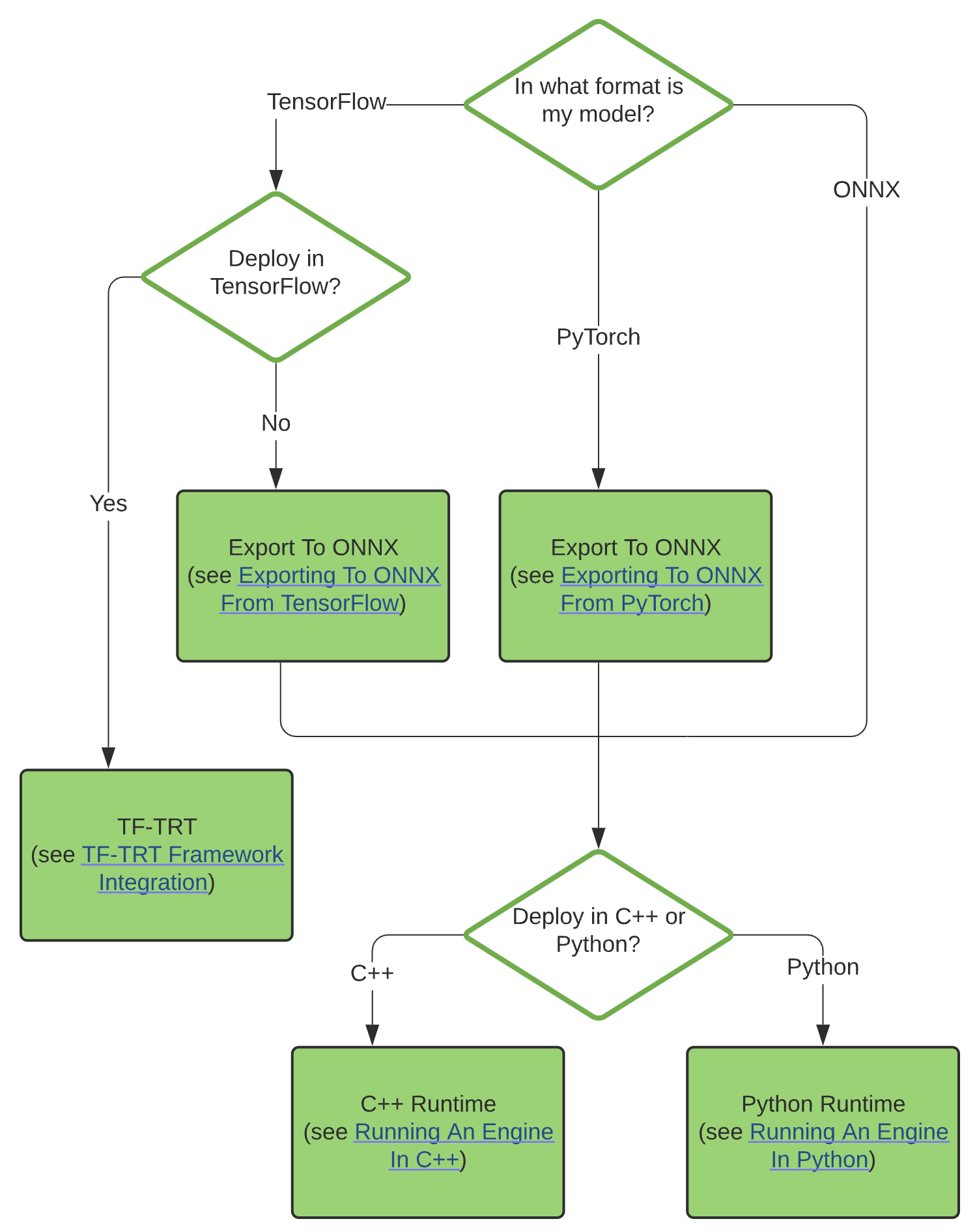
Support#
While creating a serialised TensorRT engine, except using TF-TRT or ONNX, for higher customisability one can also manually construct a network using the TensorRT API (C++ or Python)
TensorRT also includes a standalone runtime with C++ and Python bindings, apart from directly using NVIDIA’s Triton Inference server for deployment.
ONNX has a TensorRT backend that parses ONNX models for execution with TensorRT, having both Python and C++ support. Current full list of supported ONNX operators for TensorRT is maintained here. It only supports DOUBLE, FLOAT32, FLOAT16, INT8 and BOOL ONNX data types, and limited support for INT32, INT64 and DOUBLE types.
NVIDIA also kept few tooling support around TensorRT:
trtexec: For easy generation of TensorRT engines and benchmarking.Polygraphy: A Deep Learning Inference Prototyping and Debugging Toolkittrt-engine-explorer: It contains Python packagetrexto explore various aspects of a TensorRT engine plan and its associated inference profiling data.onnx-graphsurgeon: It helps easily generate new ONNX graphs, or modify existing ones.polygraphy-extension-trtexec: polygraphy extension which adds support to run inference withtrtexecfor multiple backends, including TensorRT and ONNX-Runtime, and compare outputs.
pytorch-quantizationandtensorflow-quantization: For quantisation aware training or evaluating when using Pytorch/Tensorflow.
Limitations#
Currently every model checkpoint one creates needs to be recompiled first to ONNX and then to TensorRT, so for using microsoft/LoRA it has to be added into the model at compile time. More issues can be found in this reddit post.
INT4 and INT16 quantisation is not supported by TensorRT currently. Current support on quantisation can be found here.
Many ONNX operators are not yet supported by TensorRT and few supported ones have restrictions.
Supports no Interoperability since conversion to onnx or TF-TRT format is a necessary step and has intricacies which needs to be handled for custom requirements.
FasterTransformer#
Work in Progress
Feel free to open a PR :)
Future#
Feedback
This chapter is still being written & reviewed. Please do post links & discussion in the comments below, or open a pull request!
See also:
Feedback
Missing something important? Let us know in the comments below, or open a pull request!