Desktop Apps#
While ChatGPT and GPT-4 have taken the world of AI by storm in the last half year, open-source models are catching up. And there has been a lot of ground to cover, to reach OpenAI model performance. In many cases, ChatGPT and GPT-4 are clear winners as compared to deploying LLMs on cloud servers – due to costs per OpenAI API request being relatively cheap compared with model hosting costs on cloud services like AWS, Azure, and Google Cloud. But, open-source models will always have value over closed APIs like ChatGPT/GPT-4 for certain business cases. Folks from industries like legal, healthcare, finance etc. – have concerns over data and customer privacy.
A new and exciting area are desktop apps that support running power LLMs locally. There is an argument to be made that successful desktop apps are more useful than cloud based services in some sensitive cases. This is because data, models, and the app can all be ran locally on typically available hardware. Here, I go through some of the up and coming solutions for LLM desktop apps – their benefits, limitations, and comparisons between them.
Desktop App |
Supported Models |
GPU support |
Layout |
Configuration |
Extra Features |
OS |
Future Roadmap |
|---|---|---|---|---|---|---|---|
🟡 GGML |
🟢 Yes |
Clean, clear tabs. |
Hardware config choices (GPU, RAM, etc.). Can choose multiple inference params (temperature, repeat penalty, etc.). |
Local server deployments |
Windows, Linux, MacOS |
Not mentioned |
|
🟡 GGML |
🔴 No |
Unclear tabs. |
Minimal hardware config options. Can choose inference params. |
Contribute & use training data from the GPT4All datalake |
Windows, Linux, MacOS |
||
🟡 GGML |
🔴 No |
Cluttered UI. |
Some hardware config options. Unique inference/app params e.g. scenarios. |
Cool story, character, and adventure modes |
Windows, Linux, MacOS |
Not mentioned |
|
🟡 GGML |
🔴 No |
Clear tabs. |
Minimal hardware config options. Can choose inference params. |
Light/dark modes |
Windows, Linux, MacOS |
||
🔴 few GGML models |
🟡 Yes (metal) |
Basic, terminal-based UI. |
Multiple hardware configurations, need to save as a file prior to running. Multiple inference params, need to save as a file. |
Run from terminal |
MacOS |
||
🔴 llamafile models |
🟢 Yes |
Clean, simple interface. |
Minimal hardware configurations. |
Run from terminal, invokes the default browser. |
Windows, Linux, BSD, MacOS |
LM Studio#
LM Studio is an app to run LLMs locally.
UI and Chat#
LM Studio is a desktop application supported for Windows and Mac OS that gives us the flexibility to run LLMs on our PC. You can download any ggml model from the HuggingFace models hub and run the model on the prompts given by the user.
The UI is pretty neat and well contained:
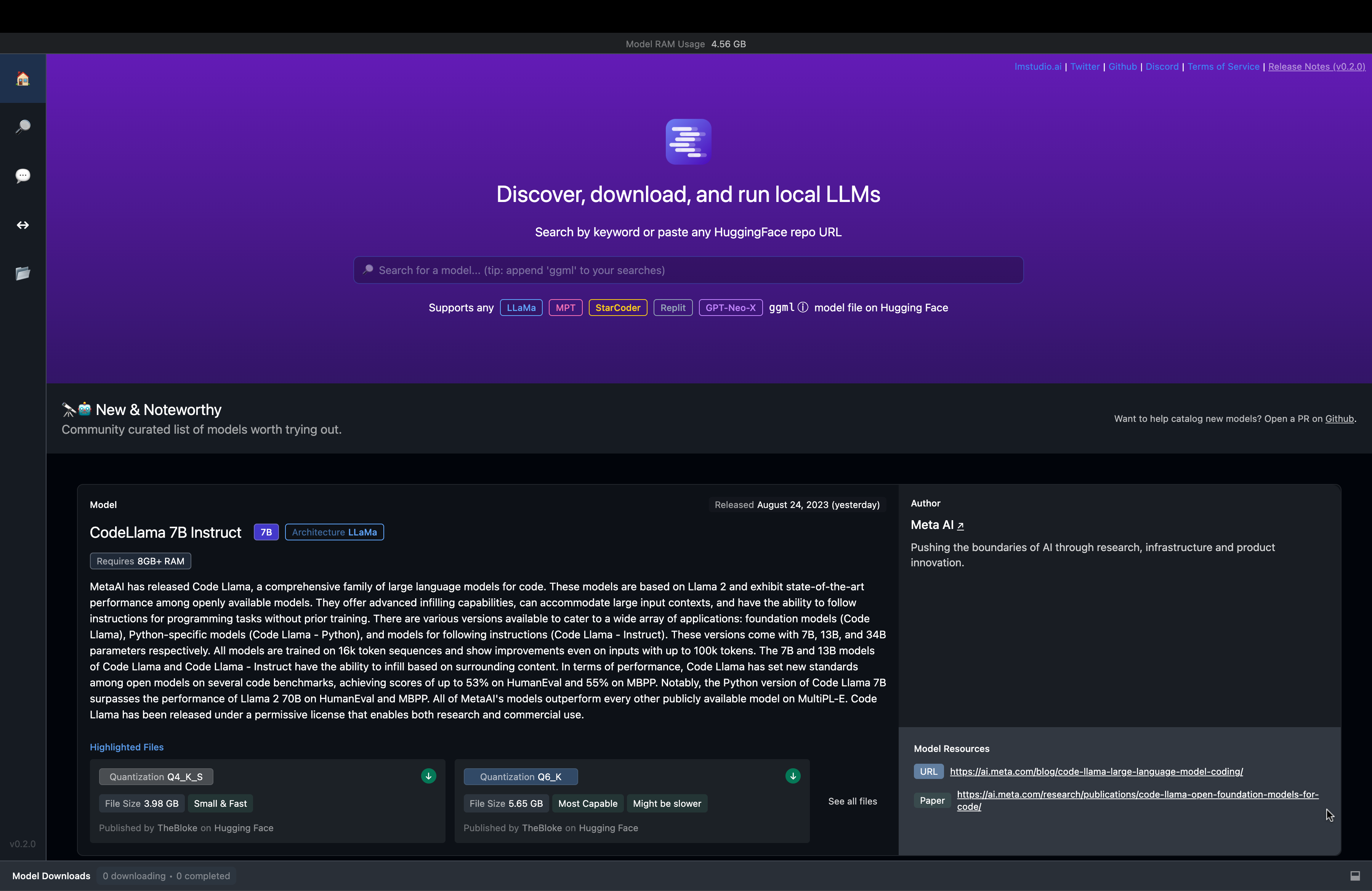
Fig. 69 LM Studio UI#
There’s a search bar that can be used to search for models from the HuggingFace models to power the chat.
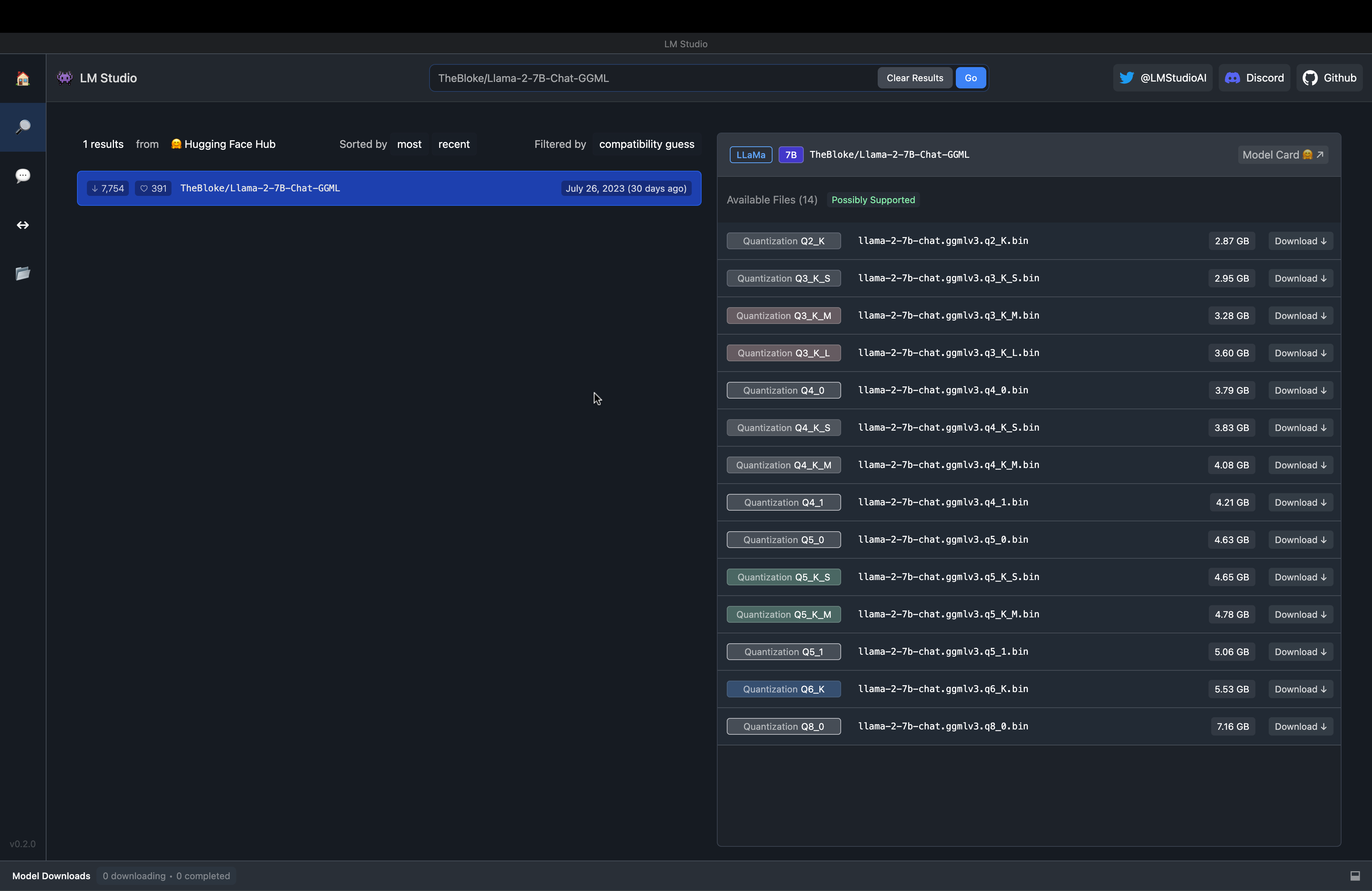
Fig. 70 LM Studio Model Search#
The Chat UI component is similar to ChatGPT to have conversations between the user and the assistant.
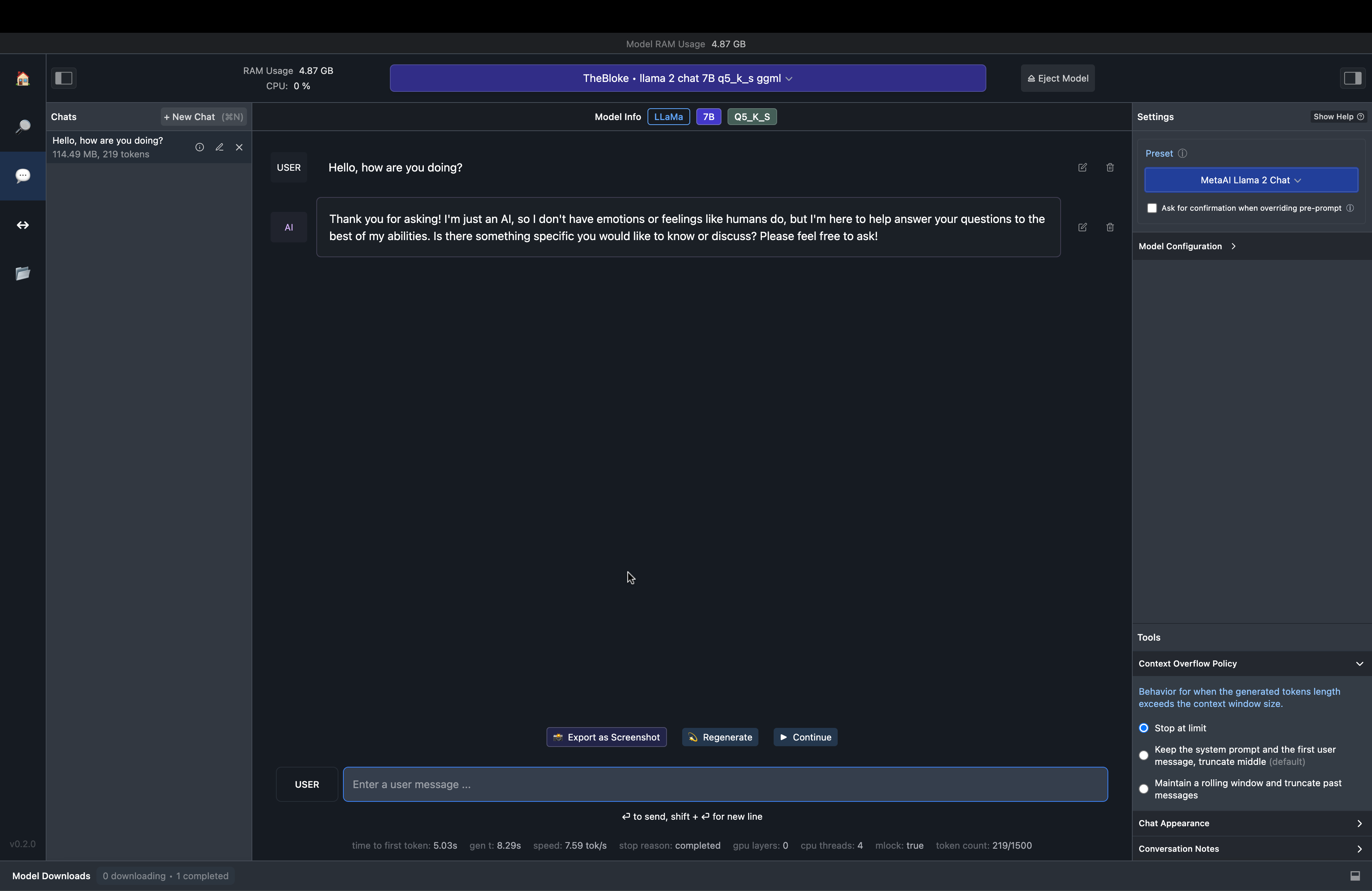
Fig. 71 LM Studio Chat Interface#
This is how the TheBloke/Llama-2-7B-Chat-GGML/llama-2-7b-chat.ggmlv3.q5_K_S.bin responds to a simple conversation starter.

Fig. 72 LM Studio Chat Example#
Local Server#
One useful aspect is the ability to build a Python or Node.js application based on an underlying LLM.
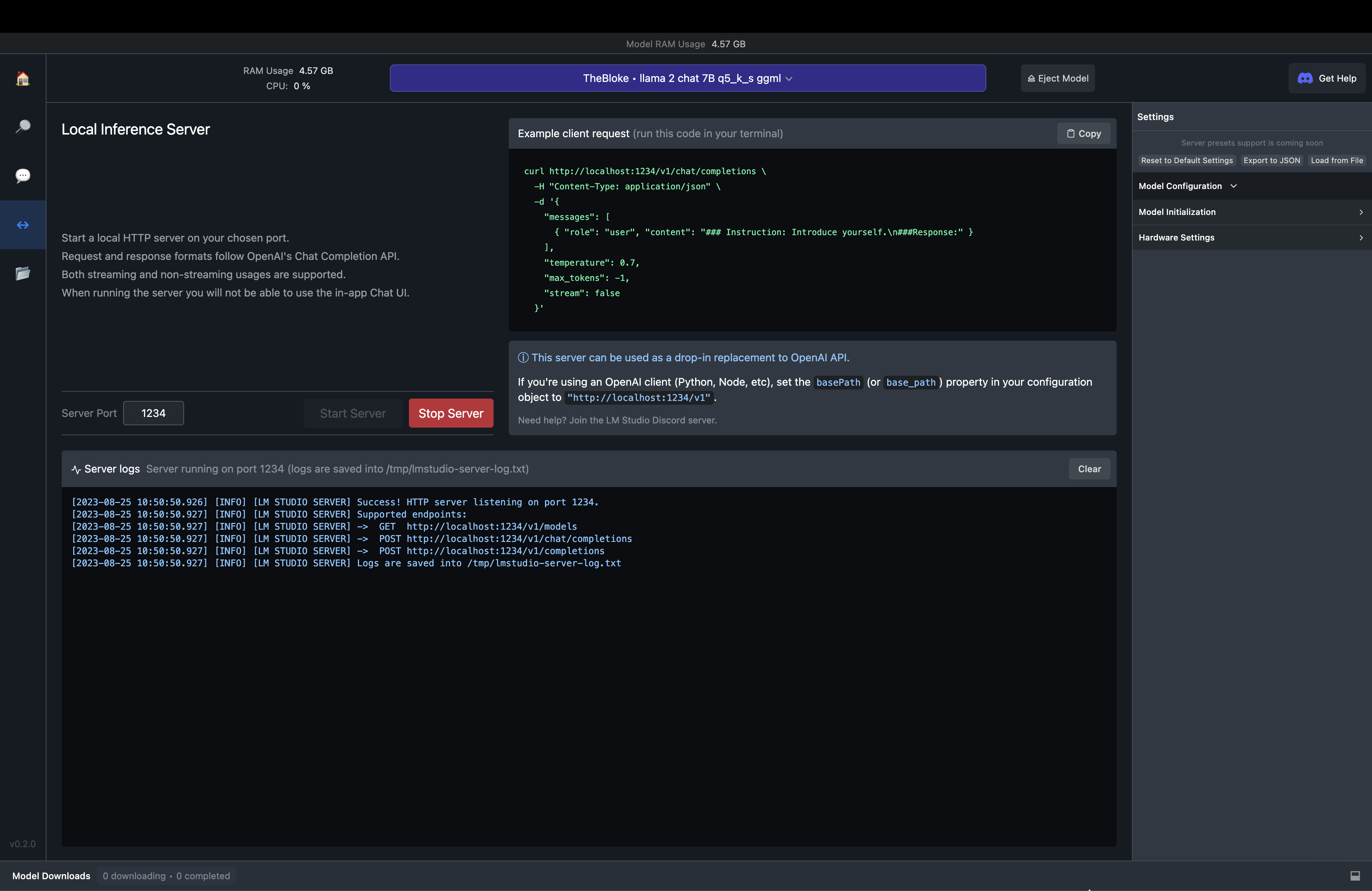
Fig. 73 LM Studio Local Server#
This enables the user to build applications that are powered by LLMs and using ggml models from the HUggingFace model library (without API key restrictions).
Think of this server like a place where you make API calls to and get the response. The only change is that this is a local server and not a cloud based server. This makes it quite exciting to use the hardware in your system to power the LLM application that you are building.
Let’s spin up the server by hitting the Start server button🎉. That was a quick one and by default it is served in port 1234 and if you want to make use of some other port then you can edit that left to the Start server button that you pressed earlier. There are also few parameters that you can modify to handle the request but for now let’s leave it as default.
Go to any Python editor of your choice and paste the following code by creating a new .py file.
import openai
# endpoint:port of your local inference server (in LM Studio)
openai.api_base='http://localhost:1234/v1'
openai.api_key='' # empty
prefix = "### Instruction:\n"
suffix = "\n### Response:"
def get_completion(prompt, model="local model", temperature=0.0):
formatted_prompt = f"{prefix}{prompt}{suffix}"
messages = [{"role": "user", "content": formatted_prompt}]
print(f'\nYour prompt: {prompt}\n')
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature)
return response.choices[0].message["content"]
prompt = "Please give me JS code to fetch data from an API server."
response = get_completion(prompt, temperature=0)
print(f"LLM's response:{response}")
This is the code that I ran using the command python3 <filename>.py and the results from server logs and terminal produced are shown below:
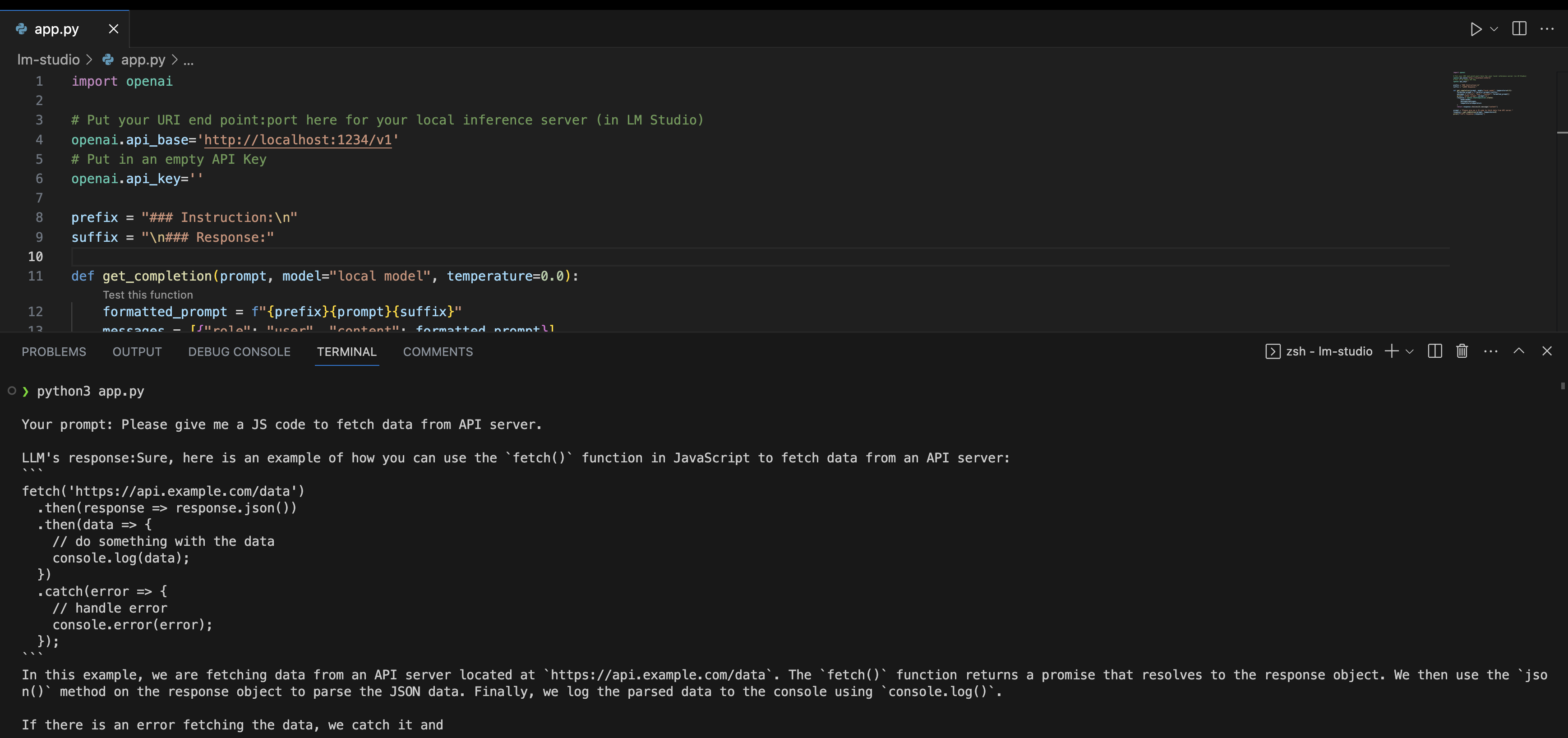
Fig. 74 LM Studio Local Server Example#
Model Configurations & Tools#
By default we have a few presets already provided by LM studio but we can tweak them and create a preset of our own to be used elsewhere. The parameters that are modifiable are:
🛠️ Inference parameters: These gives the flexibility to change the
temperature,n_predict, andrepeat_penalty↔️ Input prefix and suffix: Text to add right before, and right after every user message
␂ Pre-prompt / System prompt: Text to insert at the very beginning of the prompt, before any user messages
📥 Model initialisation:
m_lockwhen turned on will ensure the entire model runs on RAM.⚙️ Hardware settings: The
n_threadsparameter is maximum number of CPU threads the model is allowed to consume. If you have a GPU, you can turn on then_gpu_layersparameter. You can set a number between 10-20 depending on the best value, through experimentation.
Tools focus on the response and UI of the application. The parameters modifiable are as follows:
🔠
Context overflow policy: Behaviour of the model for when the generated tokens length exceeds the context window size🌈
Chat appearance: Either plain text (.txt) or markdown (.md)📝
Conversation notes: Auto-saved notes for a specific chat conversation
Features#
💪 Leverages the power of your machine to run the model i.e. more your machine is powerful then you can utilise this to the fullest reach.
🆕 The ability to download the model from HuggingFace gives power to test the latest of models like LLaMa or any other new ones hosted publicly in HuggingFace. Supported models include MPT, Starcoder, Replit, GPT-Neo-X more generally that are of the type
ggml💻 Available for both Windows and Mac.
🔌 Models can be run entirely offline as they are downloaded and reside locally in your machine.
💬 Access the app using Chat UI or local server
GPT4All#
The GPT4All homepage states that
GPT4All is an ecosystem to train and deploy powerful and customised large language models that run locally on consumer grade CPUs.
UI and Chat#
The UI for GPT4All is quite basic as compared to LM Studio – but it works fine.
Fig. 75 GPT4All UI#
However, it is less friendly and more clunky/ has a beta feel to it. For one, once I downloaded the LLaMA-2 7B model, I wasn’t able to download any new model even after restarting the app.
Local Server#
Like LM Studio, there is a support for local server in GPT4All. But it took some time to find that this feature exists and was possible only from the documentation. The results seem far better than LM Studio with control over number of tokens and response though it is model dependent. Here’s the code for the same:
import openai
openai.api_base = "http://localhost:4891/v1"
openai.api_key = ""
# Set up the prompt and other parameters for the API request
prompt = "Who is Michael Jordan?"
model = "Llama-2-7B Chat"
# Make the API request
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=199,
temperature=0.28,
top_p=0.95,
n=1,
echo=True,
stream=False)
# Print the generated completion
print(response)
The response can be found for the example prompt:

Fig. 76 GPT4All UI Example#
Model Configurations & Tools#
As you can see – there is not too much scope for model configuration, and unlike LM Studio – I couldn’t use my GPU here.
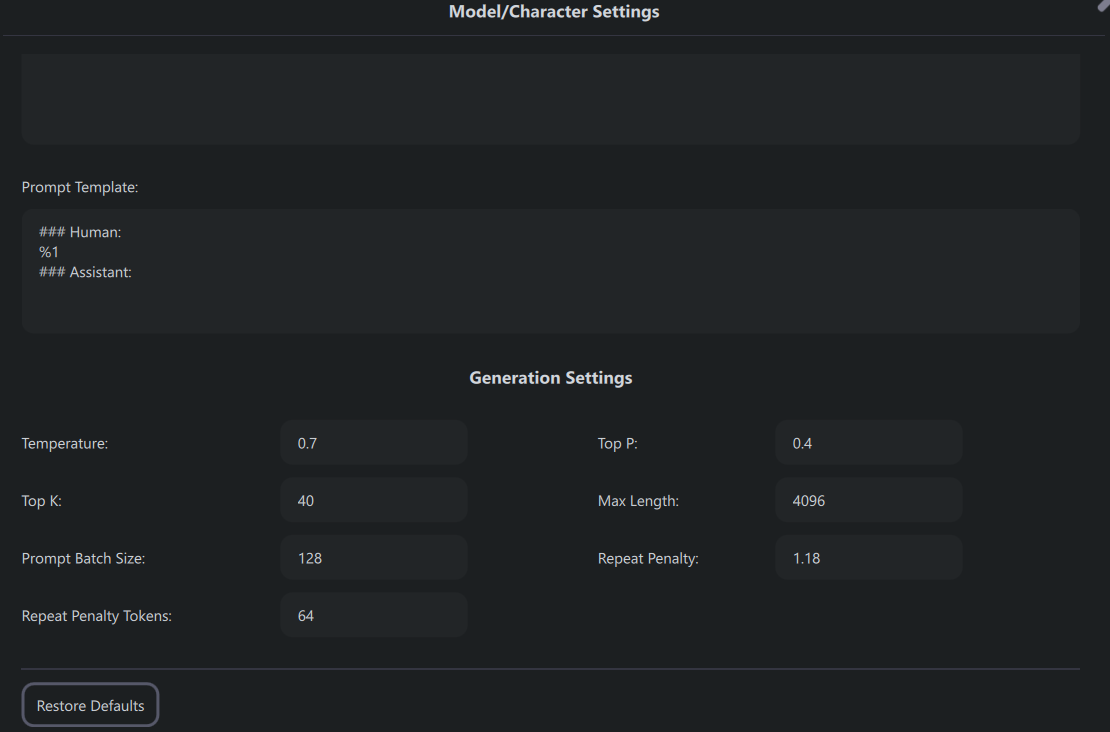
Fig. 77 GPT4All UI Model Configuration#
koboldcpp#
LostRuins/koboldcpp is a fun twist on LLMs – adding game like scenarios and adventures. It supports adding base ggml models as the LLM engine, and spinning stories based on user inputs.
UI and Chat#
The UI is pretty basic – and you get some surprising answers. Here I ask a simple icebreaker question – and you see that it responds that it is a friendly AI that likes to play games.
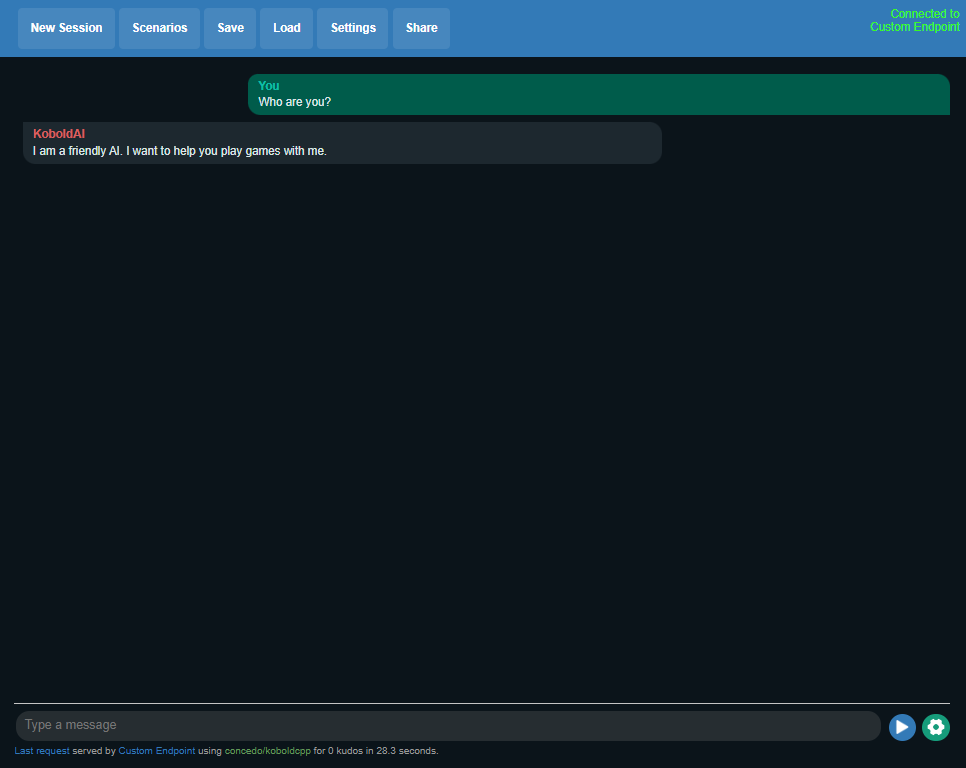
Fig. 78 koboldcpp UI#
Scenarios#
You can also enter different sorts of scenarios and modes.
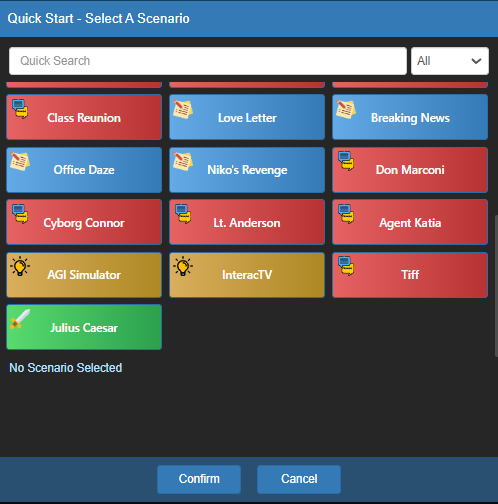
Fig. 79 koboldcpp Scenarios#
Below is the Julius Caesar scenario!
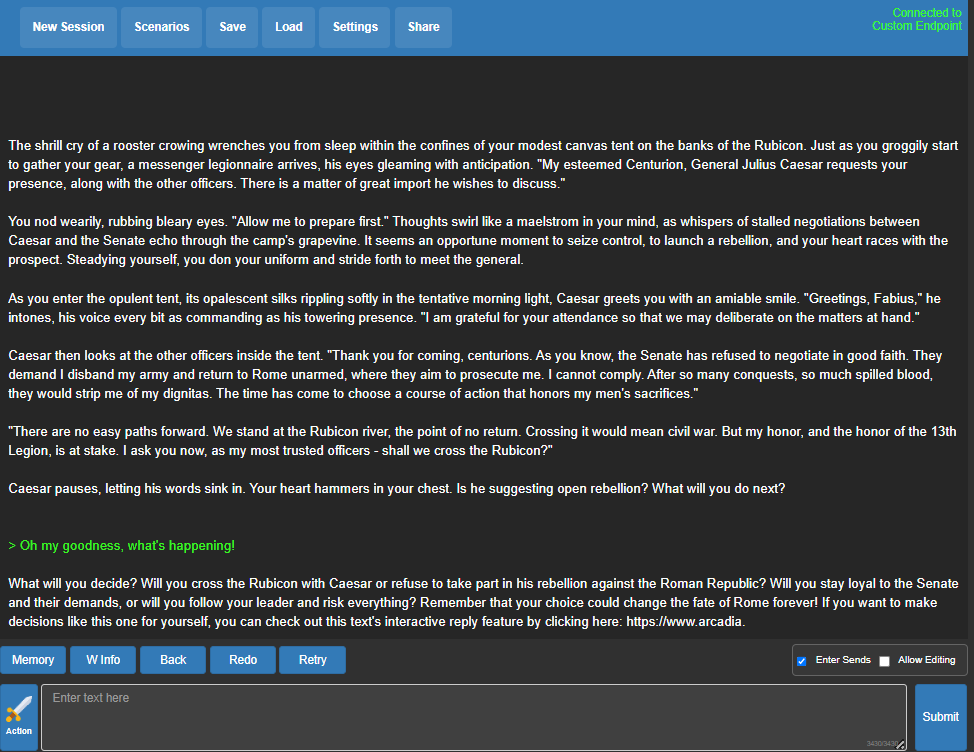
Fig. 80 koboldcpp Julius Caesar Chat#
Model Configuration and Tools#
Many of the model configurations are similar to the default that is offered. But there are some interesting twists like story mode, adventure mode, and instruct mode.
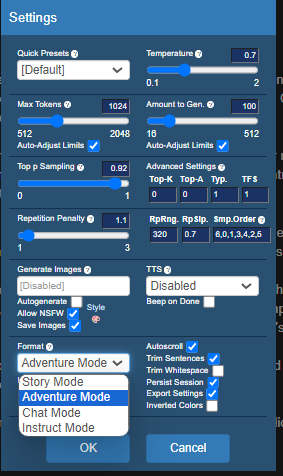
Fig. 81 koboldcpp Julius Model Configuration#
local.ai#
The local.ai App from louisgv/local.ai (not to be confused with LocalAI from mudler/LocalAI) is a simple application for loading LLMs after you manually download a ggml model from online.
UI and Chat#
The UI and chat are pretty basic. One bug that I noticed was that it wasn’t possible to load models from the UI – I had to manually download the model and then use the app.
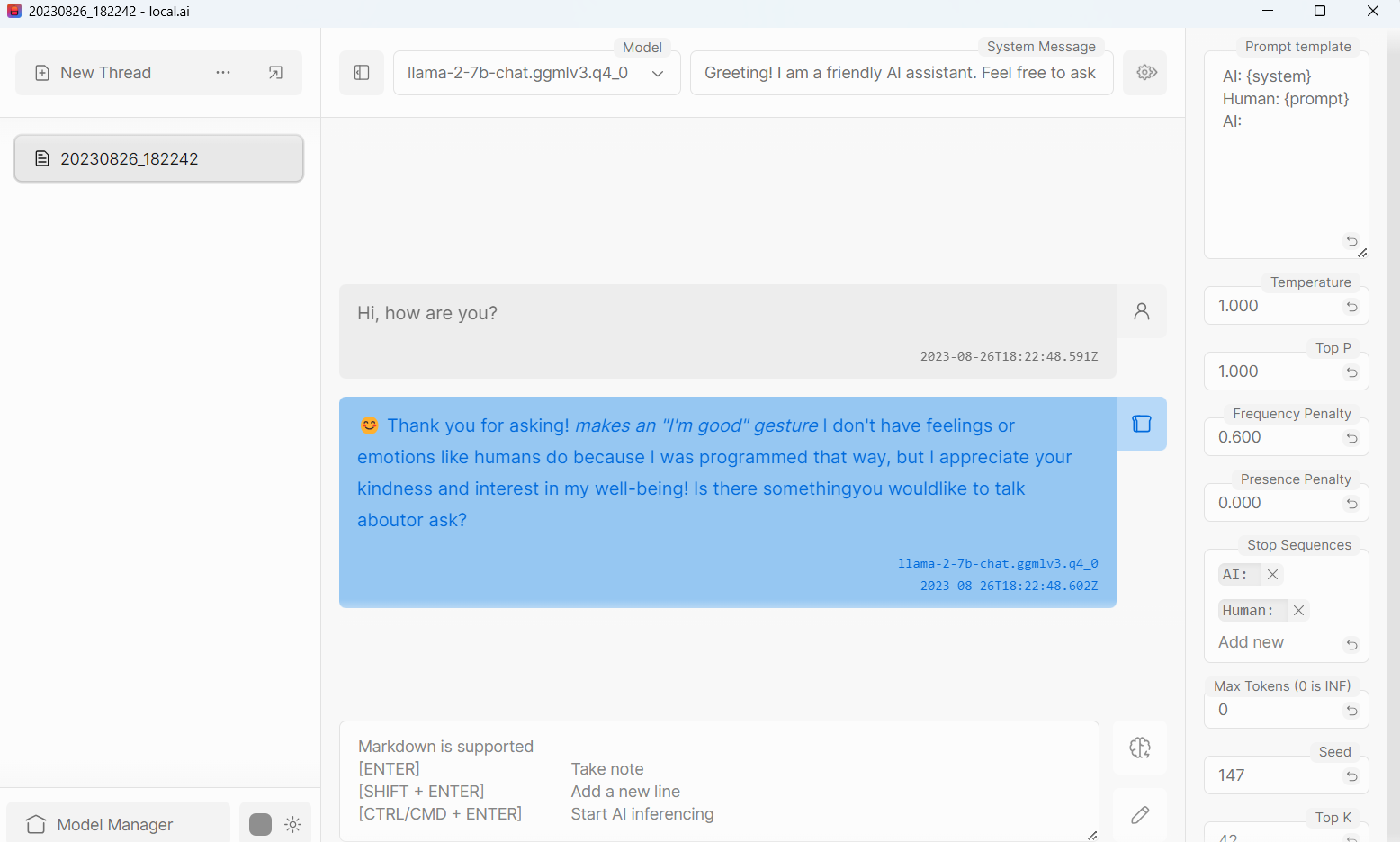
Model Configuration and Tools#
Pretty standard prompt related configurations. It appears there is no GPU.
Ollama#
Ollama is an LLM based conversational chat bot that can be run from a MAC terminal. It is simple to get started. Currently, it is available only for the Mac OS but support for Windows and Linux are coming soon.
UI and Chat#
Neat clean and crisp UI, just >>> in the terminal and you can paste your prompt. The response time will vary according to the model size but responses are mostly acceptable. I tested the LLaMA model which is the most recently supported model and the results were good.
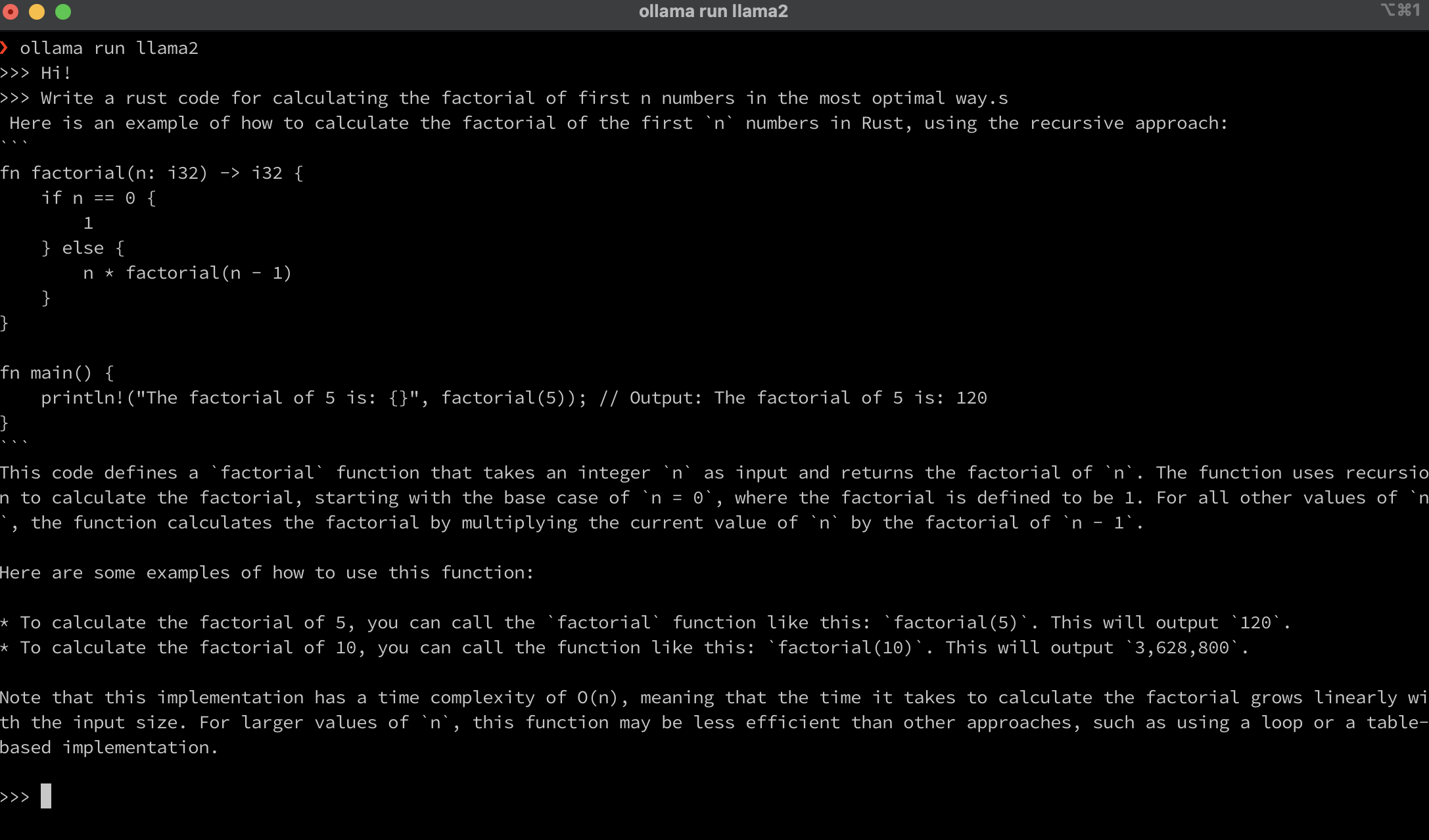
Fig. 83 Ollama Example#
Note: It just takes some time initially for the model to download locally, but later whenever you need to access the model there is no lag in accessing the requested model.
Model Configuration and Tools#
The list of ~20 models can be accessed here.
They are constantly growing and multiple changes have happened quite recently. It can support models ranging from lite to robust models.
It also has special support for specific functionality like performing Mathematical calculations. There is a WizardMath model that addresses these use case – read more about this in their official blog published by the Ollama team.
Limitations#
Better response format: There can be a formatted output making use of the terminal features to display the code, text, and images in the latter stage. This will make the output more readable and consistent to the user.
Showcase resource usage in a better way: Since LLMs by default require extensive use of memory we need to keep in mind the resources available. So while working in a terminal such details will not be explicitly available and can sometimes consume all the memory which can cause the application or the entire system to crash.
Support for custom models (from local): There is support to load models downloaded from the internet and run them locally by using the command:
ollama run "model location in the system"
llamafile#
The objective of llamafile is to enhance the accessibility of open-source large language models (LLMs) for both developers and end users. To achieve this, they have merged llama.cpp with Cosmopolitan Libc, creating a framework that simplifies the complexity of LLMs into a single-file executable known as a llamafile. This executable can be run locally on most computers without the need for installation. The framework is licensed under the Apache License, Version 2.0. This combination enables developers and end users to fully utilize large language models (LLMs). Through the implementation of the llamafile approach, they have unlocked the potential of LLMs on a local scale, paving the way for exciting new opportunities across a wide range of applications. To experience it firsthand, the llamafile developers recommend downloading their example llamafile for the LLaVA model, which is licensed under LLaMA 2, OpenAI. LLaVA is an LLM that goes beyond mere chat capabilities; it also allows users to upload images and ask questions related to them. Importantly, all of this functionality occurs locally, ensuring that no data ever leaves the computer.
It is important to note that if there are any issues with compiling and dynamically linking GPU support, llamafile has a contingency plan in place. In such cases, the system will automatically switch to CPU inference, ensuring uninterrupted performance and accurate results.
Under Linux, the dynamic compilation of Nvidia cuBLAS GPU support is possible under certain conditions. Firstly, the presence of the cc compiler is required. Secondly, the -ngl 35 flag must be passed to activate the GPU. Lastly, the CUDA developer toolkit must be installed on the machine, and the nvcc compiler should be accessible through the system’s path.
For Windows users, utilizing the GPU requires the following two steps: first, make sure that the released binaries are used. Secondly, pass the -ngl 35 flag. Additionally, it is essential to have an NVIDIA graphics card that supports CUDA, as AMD GPUs are not currently supported. If users prefer to use CUDA via WSL, one can enable Nvidia CUDA on WSL and run the llamafiles within WSL. However, it is worth noting that Windows users may face limitations with some of our example llamafiles due to the maximum executable file size restriction of 4 GB imposed by the Windows operating system. But don’t worry, the llamafile framework offers support for external weight (see documention for details).
On the Apple Silicon, if Xcode is installed, everything should seamlessly function without any issues.
Feedback
Missing something important? Let us know in the comments below, or open a pull request!