Fine-tuning#
Work in Progress
This chapter is still being written & reviewed. Please do post links & discussion in the comments below, or open a pull request!
Some ideas:
https://gist.github.com/veekaybee/be375ab33085102f9027853128dc5f0e#training-your-own
Why You (Probably) Don’t Need to Fine-tune an LLM (instead, use few-shot prompting & retrieval-augmented generation)
Fine-tuning LLaMA-2: A Comprehensive Case Study for Tailoring Models to Unique Applications (fine-tuning LLaMA-2 for 3 real-world use cases)
Easy-to-use LLM fine-tuning framework (LLaMA-2, BLOOM, Falcon, Baichuan, Qwen, ChatGLM2)
h2oai, etc.
The History of Open-Source LLMs: Better Base Models (part 2) (LLaMA, MPT, Falcon, LLaMA-2)
For bespoke applications, models can be trained on task-specific data. However, training a model from scratch is seldom required. The model has already learned useful feature representations during its initial (pre) training, so it is often sufficient to simply fine-tune. This takes advantage of transfer learning, producing better task-specific performance with minimal training examples & resources – analogous to teaching a university student without first reteaching them how to communicate.
Transfer Learning versus Fine-tuning#
Both transfer learning and fine-tuning modify a pre-trained model for a domain/task-specific use, and thus both terms are often used interchangeably. However, there are key differences.
Description |
Transfer Learning |
Fine-tuning |
|---|---|---|
Based on a model pre-trained on a large generic dataset |
yes |
yes |
Freeze pre-trained model layers |
most or all |
none (“full” fine-tuning) or a few |
Head layer |
append a new head |
replace existing head or leave as-is |
Train on domain-specific data until unfrozen layers converge |
yes |
yes |
Transfer Learning#
From Wikipedia definition, Transfer learning is a technique in machine learning in which knowledge learned from task is re-used in order to boost performance for some related task. For working on transfer learning, you start with a pre-trained model. A pre-trained model is a deep learning model trained on a very large dataset (can be image text etc.). Most of the times, these pre-trained models are huge classification models trained on huge data with numerous number of classes. During the course of training these models eventually learns features and representations to minimize the loss.
Hence before starting Transfer Learning, we take out the layers responsible for classification (pen-ultimate layers) and treat that as our feature extractor. We leverage this knowledge coming from the feature extractor (pre-trained model) to train a smaller model confined to a very specific domain-specific task. The key is that “frozen” layers remain unchanged – retaining the original abilities of the pre-trained model – and act as general & robust feature extractors.
Fig. 52 Transfer Learning#
Examples:
Computer vision: take the ResNet-50 pre-trained on the ImageNet dataset and replace its last layer with the head of an object-detecting model (such as Faster R-CNN). This modified model can now be trained to draw bounding boxes and classify images from the cats-vs-dogs dataset.
Natural language processing: take a BERT model, that was pre-trained on extensive text data, such as the BookCorpus dataset. Replace BERT’s final layer with a simple classifier or Multi-Layer Perceptron (MLP) layers. These final layers can then be trained on the tweet sentiment classification dataset to classify twitter sentiments.
Use cases:
NOTE: We can even extend the process of transfer learning by unfreezing some layers of pre-trained model and retraining them along with our smaller model. This additional step helps the model to adapt on newer domain-specific task or out of distribution tasks.
Limited data: when domain-specific dataset size is small, a large model cannot be trained end-to-end without overfitting. However if the model is mostly a frozen general feature extractor, then the subsequent trainable layers are less likely to overfit.
Limited compute and time: retraining a large model from scratch requires a lot of compute resources and time. This is unnecessary if similar performance can be achieved through transfer learning (training just part of a large model).
The key difference here is none (or few) of the pre-trained model’s weights are frozen. The pre-training process can be considered an intelligent weight initialisation prior to training on a domain-specific dataset. Essentially, the pre-training will leave the model weights close to a global (general) optimum, while the domain-specific training will find a local (task-specific) optimum.
Fine-Tuning#
From Wikipedia’s definition, Fine-tuning is an approach to transfer learning in which weights of a pre-trained model is trained on a new data. In some case we retrain the whole model on our domain-specific dataset or in other cases, we just fine-tune on only a subset of the layers. Through fine-tuning, we are adapting our existing pre-trained model on a task-specific dataset.

Fig. 53 Fine Tuning#
Examples:
Computer vision: for segmentation in cases where fine-grained detail is important (e.g. finding individual cells in medical imaging, or detecting objects in satellite images), transfer learning might not be accurate enough.
Natural language processing: an LLM such as Persimmon 8B – used in general purpose text completion – can be adapted to do summarisation. Adding a few layers (transfer learning) may not be enough to do summarisation well, and hence full fine-tuning is required.
Use cases:
Performance: when transfer learning is not accurate enough, and enough domain-specific data is available to make use of fine-tuning without overfitting.
Note that fine-tuning typically required much more compute resources, time, and data than transfer learning.
Fine-tuning LLMs#
When an LLM does not produce the desired output, engineers think that by fine-tuning the model, they can make it “better”. But what exactly does “better” mean in this case? It’s important to identify the root of the problem before fine-tuning the model on a new dataset.
Common LLM issues include:
The model lacks knowledge on certain topics
RAG can be used to solve this problem
The model’s responses do not have the proper style or structure the user is looking for
Fine-tuning or few-shot prompting is applicable here
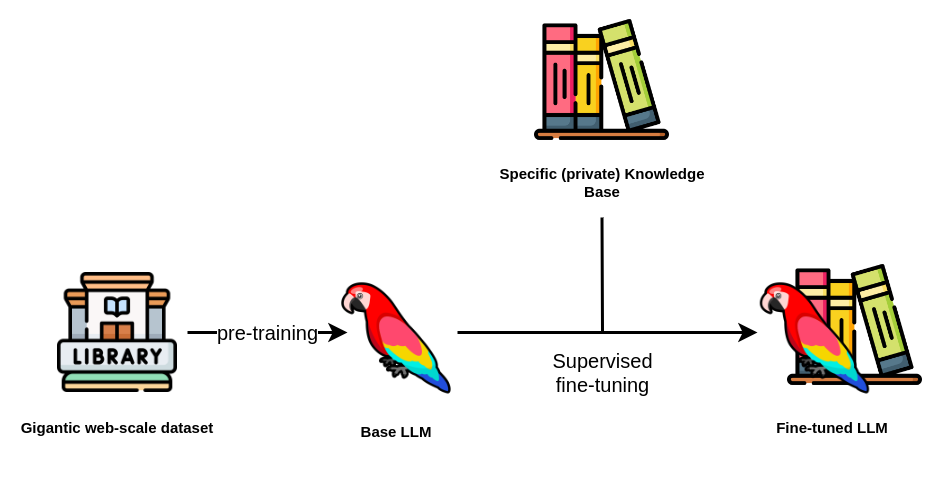
Fig. 54 Fine-tuning LLMs#
A baseline LLM model cannot answer questions about content is hasn’t been trained on [139]. The LLM will make something up, i.e., hallucinate. To fix issues like this, RAG is a good tool to use because it provides the LLM with the context it needs to answer the question.
On the other hand, if the LLM needs to generate accurate SQL queries, RAG is not going to be of much help here. The format of the generated output matters a lot, so fine-tuning would be more useful for this use case. a Here are some examples of models that have been fine-tuned to generate content in a specific format/style:
Gorilla LLM - This LLM was fine-tuned to generate API calls.
LLaMA-2 chat - The “chat” version of LLaMA is fine-tuned on conversational data.
Code LLaMA - A fine-tuned LLaMA-2 model designed for code generation.
RAG#
RAG is a method used to boost the accuracy of LLMs by injecting relevant context into an LLM prompt. It works by connecting to a vector database and fetches only the information that is most relevant to the user’s query. Using this technique, the LLM is provided with enough background knowledge to adequately answer the user’s question without hallucinating.
RAG is not a part of fine-tuning, because it uses a pre-trained LLM and does not modify it in any way. However, there are several advantages to using RAG:
Boosts model accuracy
Leads to less hallucinations by providing the right context
Less computing power required
Unlike fine-tuning, RAG does not need to re-train any part of the model. It’s only the models prompt that changes.
Quick and easy setup
RAG does not require much LLM domain expertise. You don’t need to find training data or corresponding labels. Most pieces of text can be uploaded into the vector db as is, without major modifications.
Connect to private data
Using RAG, engineers can connect data from SaaS apps such as Notion, Google Drive, HubSpot, Zendesk, etc. to their LLM. Now the LLM has access to private data and can help answer questions about the data in these applications.
RAG plays a key role in making LLMs useful, but it can be a bit tedious to set up. There are a number of open-source project such as run-llama/llama_index which can help make the process a bit easier.
Fine-tuning Image Models#
Fine tuning computer vision based models is a common practice and is used in applications involving object detection, object classification, and image segmentation.
For these non-generative AI use-cases, a baseline model like Resnet or YOLO is fine-tuned on labelled data to detect a new object. Although the baseline model isn’t initially trained for the new object, it has learned the feature representation. Fine-tuning enables the model to rapidly acquire the features for the new object without starting from scratch.
Data preparation plays a big role in the fine-tuning process for vision based models. An image of the same object can be taken from multiple angles, different lighting conditions, different backgrounds, etc. In order to build a robust dataset for fine-tuning, all of these image variations should be taken into consideration.
Fine-tuning AI image generation models#
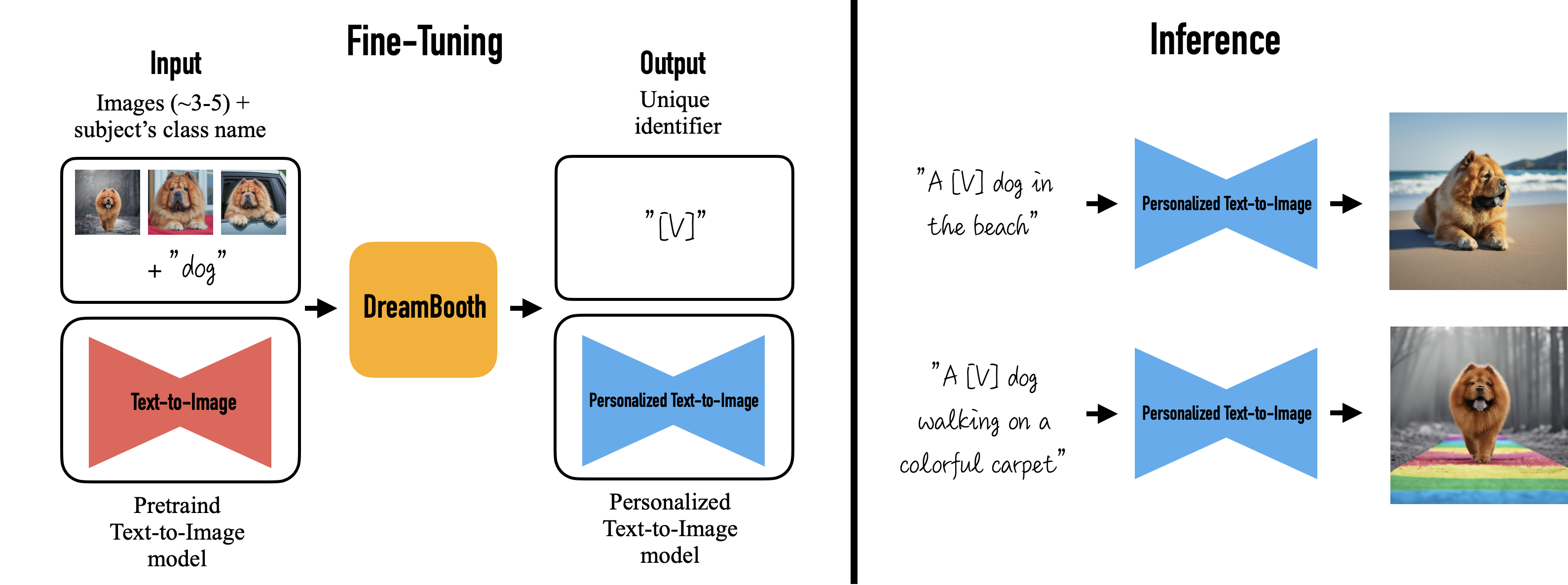
Models such as Stable Diffusion can also be tailored through fine-tuning to generate specific images. For instance, by supplying Stable Diffusion with a dataset of pet pictures and fine-tuning it, the model becomes capable of generating images of that particular pet in diverse styles.
The dataset for fine-tuning an image generation model needs to contain two things:
Text: What is the object in the image
Image: The picture itself
The text prompts describe the content of each image. During fine-tuning, the text prompt is passed into the text encoder portion of Stable Diffusion while the image is fed into the image encoder. The model learns to generate images that match the textual description based on this text-image pairing in the dataset [140].
Fine-tuning Audio Models#

Fig. 56 Audio Generation Fine-tuning#
Speech-to-text models like Whisper can also be fine-tuned. Similar to fine-tuning image generation models, speech-to-text models need two pieces of data:
Audio recording
Audio transcription
Preparing a robust dataset is key to building a fine-tuned model. For audio related data there are a few things to consider:
Acoustic Conditions:
Background noise levels - more noise makes transcription more difficult. Models may need enhanced noise robustness.
Sound quality - higher quality audio with clear speech is easier to transcribe. Low bitrate audio is challenging.
Speaker accents and voice types - diversity of speakers in training data helps generalise.
Audio domains - each domain like meetings, call centers, videos, etc. has unique acoustics.
Dataset Creation:
Quantity of training examples - more audio-transcript pairs improves accuracy but takes effort.
Data collection methods - transcription services, scraping, in-house recording. Quality varies.
Transcript accuracy - high precision transcripts are essential. Poor transcripts degrade fine-tuning.
Data augmentation - random noise, speed, pitch changes makes model robust.
Importance of data#
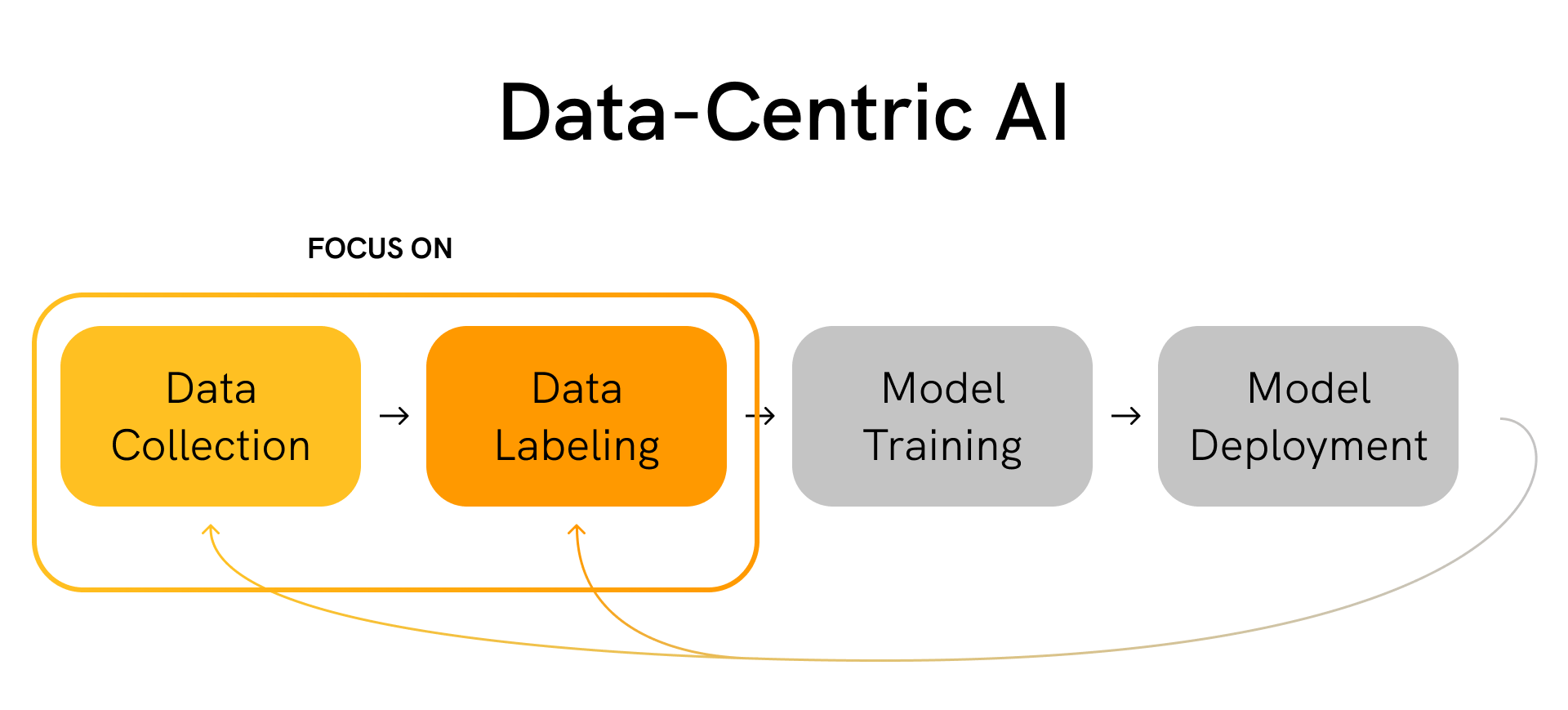
Fig. 57 Data centric AI#
The performance of a fine-tuned model largely depends on the quality and quantity of training data.
For LLMs, the quantity of data can be an important factor when deciding whether to fine-tune or not. There have been many success stories of companies like Bloomberg [141], Mckinsey, and Moveworks that have either created their own LLM or fine-tuned an existing LLM which has better performance than ChatGPT on certain tasks. However, tens of thousands of data points were required in order to make these successful AI bots and assistants. In the Moveworks blog post, the fine-tuned model which surpasses the performance of GPT-4 on certain tasks, was trained on an internal dataset consisting of 70K instructions.
In the case of computer vision models, data quality can play a significant role in the performance of the model. Andrew Ng, a prominent researcher and entrepreneur in the field of AI, has been an advocate of data centric AI in which the quality of the data is more important than the sheer volume of data [142].
To summarise, fine-tuning requires a balance between having a large dataset and having a high quality dataset. The higher the data quality, the higher the chance of increasing the model’s performance.
Model |
Task |
Hardware |
Data |
|---|---|---|---|
LLaMA-2 7B |
Text Generation |
GPU: 65GB, 4-bit quantised: 10GB |
1K datapoints |
Falcon 40B |
Text Generation |
GPU: 400GB, 4-bit quantised: 50GB |
50K datapoints |
Stable Diffusion |
Image Generation |
GPU: 6GB |
10 (using Dreambooth) images |
YOLO |
Object Detection |
Can be fine-tuned on CPU |
100 images |
Whisper |
Audio Transcription |
GPU: 5GB (medium), 10GB (large) |
50 hours |
GPU memory for fine-tuning
Most models require a GPU for fine-tuning. To approximate the amount of GPU memory required, the general rule is around 2.5 times the model size. Note that quantisation to reduce the size tends to only be useful for inference, not training-fine-tuning. An alternative is to only fine-tune some layers (freezing and quantising the rest), thus greatly reducing memory requirements.
For example: to fine-tune a float32 (i.e. 4-byte) 7B parameter model:
Future#
Fine-tuning models has been a common practice for ML engineers. It allows engineers to quickly build domain-specific models without having to design the neural network from scratch.
Developer tools for fine-tuning continue to improve the overall experience of creating one of these models while reducing the time to market. Companies like Hugging Face are building open-source tools to make fine-tuning easy. On the commercial side, companies like Roboflow and Scale AI provide platforms for teams to manage the full life-cycle of a model.
Overall, fine-tuning has become a crucial technique for adapting large pre-trained AI models to custom datasets and use cases. While the specific implementation details vary across modalities, the core principles are similar - leverage a model pre-trained on vast data, freeze most parameters, add a small tunable component customised for your dataset, and update some weights to adapt the model.
When applied correctly, fine-tuning enables practitioners to build real-world solutions using leading large AI models.
Feedback
Missing something important? Let us know in the comments below, or open a pull request!