References#
Work in Progress (TODO: move elsewhere)
important and/or related to whole book
“Catching up on the weird world of LLMs” (summary of the last few years) https://simonwillison.net/2023/Aug/3/weird-world-of-llms
“Open challenges in LLM research” (exciting post title but mediocre content) https://huyenchip.com/2023/08/16/llm-research-open-challenges.html
“Patterns for Building LLM-based Systems & Products” (Evals, RAG, fine-tuning, caching, guardrails, defensive UX, and collecting user feedback) https://eugeneyan.com/writing/llm-patterns
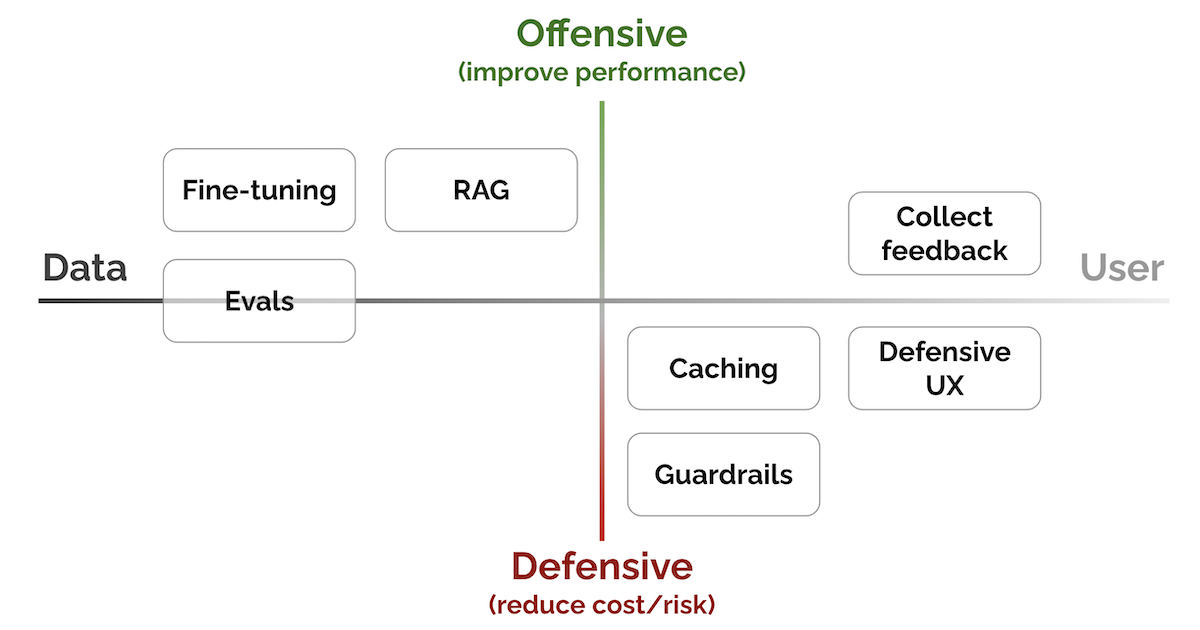
Fig. 84 LLM patterns: From data to user, from defensive to offensive#
awesome-lists (mention overall list + recently added entries)“Anti-hype LLM reading list” (foundation papers, training, deployment, eval, UX) https://gist.github.com/veekaybee/be375ab33085102f9027853128dc5f0e
… others?
open questions & future interest (pages 15 & 16): https://mlops.community/wp-content/uploads/2023/07/survey-report-MLOPS-v16-FINAL.pdf
unclassified
Couldn’t decide which chapter(s) these links are related to. They’re mostly about security & optimisation. Perhaps create a new chapter?
“How I Re-implemented PyTorch for WebGPU” (
webgpu-torch: inference & autograd lib to run NNs in browser with negligible overhead) https://praeclarum.org/2023/05/19/webgpu-torch.html“LLaMA from scratch (or how to implement a paper without crying)” (misc tips, scaled-down version of LLaMA for training) https://blog.briankitano.com/llama-from-scratch
“Swift Transformers: Run On-Device LLMs in Apple Devices” https://huggingface.co/blog/swift-coreml-llm
“Why GPT-3.5-turbo is (mostly) cheaper than LLaMA-2” https://cursor.sh/blog/llama-inference#user-content-fn-gpt4-leak
https://betterprogramming.pub/you-dont-need-hosted-llms-do-you-1160b2520526
“Low-code framework for building custom LLMs, neural networks, and other AI models” ludwig-ai/ludwig
“GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers” https://arxiv.org/abs/2210.17323
“RetrievalQA with LLaMA 2 70b & Chroma DB” (nothing new, but this guy does a lot of experiments if you wanna follow him) https://youtu.be/93yueQQnqpM
“[WiP] build MLOps solutions in Rust” nogibjj/rust-mlops-template
Casper da Costa-Luis, Nicola Sosio, Biswaroop Bhattacharjee, Skanda Vivek, Het Trivedi, Filippo Pedrazzini, and others. State of Open Source AI. Prem, first edition, 2023. URL: https://book.premai.io/state-of-open-source-ai, doi:10.5281/zenodo.10023181.
Google Cloud. MLOps: continuous delivery and automation pipelines in machine learning. 2023. URL: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning.
Red Hat, Inc. Stages of MLOps. 2023. URL: https://www.redhat.com/en/topics/ai/what-is-mlops#stages-of-mlops.
INNOQ. MLOps principles. 2023. URL: https://ml-ops.org/content/mlops-principles.
Python Core Team. Python: A dynamic, open source programming language. Python Software Foundation (PSF), 2019. URL: https://www.python.org.
G.E.P. Box. Robustness in the strategy of scientific model building. In Robert L. Launer and Graham N. Wilkinson, editors, Robustness in Statistics, pages 201–236. Academic Press, 1979. doi:10.1016/B978-0-12-438150-6.50018-2.
Akshit Mehra. How to make large language models helpful, harmless, and honest. 2023. URL: https://www.labellerr.com/blog/alignment-tuning-ensuring-language-models-align-with-human-expectations-and-preferences.
Tony Jesuthasan. Autoregressive (AR) language modeling. 2021. URL: https://tonyjesuthasan.medium.com/autoregressive-ar-language-modelling-c9fe5c20aa6e.
Wikipedia contributors. Copyleft. 2023. URL: https://en.wikipedia.org/wiki/Copyleft.
Wikipedia contributors. Fair dealing. 2023. URL: https://en.wikipedia.org/wiki/Fair_dealing.
Wikipedia contributors. Fair use. 2023. URL: https://en.wikipedia.org/wiki/Fair_use.
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. 2023. arXiv:2202.05262.
Vikas Raunak and Arul Menezes. Rank-one editing of encoder-decoder models. 2022. arXiv:2211.13317.
Clemens Mewald. The golden age of open source in AI is coming to an end. Towards Data Science, 2023. URL: https://towardsdatascience.com/the-golden-age-of-open-source-in-ai-is-coming-to-an-end-7fd35a52b786.
Technology Innovation Institute. UAE's Falcon 40B is now royalty free. 2023. URL: https://www.tii.ae/news/uaes-falcon-40b-now-royalty-free.
Benj Edwards. Meta launches LLaMA 2, a source-available AI model that allows commercial applications. 2023. URL: https://arstechnica.com/information-technology/2023/07/meta-launches-llama-2-an-open-source-ai-model-that-allows-commercial-applications.
Simon Willison. Openly licensed models. In Catching up on the weird world of LLMs. 2023. URL: https://simonwillison.net/2023/Aug/3/weird-world-of-llms/#openly-licensed-models.
The Open Knowledge Foundation. The open definition. 2023. URL: https://opendefinition.org.
Open Source Initiative. The open source definition. 2023. URL: https://opensource.org/osd.
Wikipedia contributors. Software license. 2023. URL: https://en.wikipedia.org/wiki/Software_license.
F. S. McNeilly. The enforceability of law. Noûs, 2(1):47–64, 1968. doi:10.2307/2214413.
Patrick Howell O'Neill. The US military wants to understand the most important software on earth. 2022. URL: https://www.technologyreview.com/2022/07/14/1055894/us-military-sofware-linux-kernel-open-source.
Casper da Costa-Luis. Policing FOSS. 2023. URL: https://tldr.cdcl.ml/linux-foss-warranty.
Casper da Costa-Luis. Open source is illegal. 2023. URL: https://tldr.cdcl.ml/os-is-illegal.
Wikipedia contributors. Limitations and exceptions to copyright. 2023. URL: https://en.wikipedia.org/wiki/Limitations_and_exceptions_to_copyright.
Wikipedia contributors. Google LLC v. Oracle America, Inc. 2023. URL: https://en.wikipedia.org/wiki/Google_LLC_v._Oracle_America,_Inc.
Wikipedia contributors. Authors Guild, Inc. v. Google, Inc. 2023. URL: https://en.wikipedia.org/wiki/Authors_Guild,_Inc._v._Google,_Inc.
Adam Liptak and Alexandra Alter. Challenge to Google Books is declined by supreme court. The New York Times, 2016. URL: https://www.nytimes.com/2016/04/19/technology/google-books-case.html.
Vladimir Iglovikov. Is it legal to use pre-trained models for commercial purposes? 2023. URL: pytorch/vision#2597.
OpenAI. Supported countries and territories. 2023. URL: https://platform.openai.com/docs/supported-countries.
Thomas Claburn. GitHub accused of varying Copilot output to avoid copyright allegations. The Register, 2023. URL: https://www.theregister.com/2023/06/09/github_copilot_lawsuit.
Thomas Claburn. Microsoft, OpenAI sued for $3B after allegedly trampling privacy with ChatGPT. The Register, 2023. URL: https://www.theregister.com/2023/06/28/microsoft_openai_sued_privacy.
Legal PDF. DOE v. GitHub: original complaint pertaining to copyright infringement, open source licenses & more. HackerNoon, 2023. URL: https://hackernoon.com/doe-v-github-original-complaint-pertaining-to-copyright-infringement-open-source-licenses-and-more.
Open Source Initiative. OSI approved licenses. 2023. URL: https://opensource.org/licenses.
European Commission. Cyber Resilience Act. 2022. URL: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52022PC0454.
European Commission. Product Liability Act. 2022. URL: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52022PC0495.
Casper da Costa-Luis. CRA & PLA cybersecurity laws need rewording. 2023. URL: https://tldr.cdcl.ml/CRA-PLA-cybersecurity-law-rewording-appeal.
The Python Software Foundation. The EU's proposed CRA law may have unintended consequences for the Python ecosystem. 2023. URL: https://pyfound.blogspot.com/2023/04/the-eus-proposed-cra-law-may-have.html.
Mike Milinkovich. Cyber resilience act: good intentions and unintended consequences. 2023. URL: https://eclipse-foundation.blog/2023/02/23/cyber-resilience-act-good-intentions-and-unintended-consequences.
NLnet Labs. Open-source software vs. the proposed cyber resilience act. 2023. URL: https://blog.nlnetlabs.nl/open-source-software-vs-the-cyber-resilience-act.
Casper da Costa-Luis. Open source is bad. 2023. URL: https://tldr.cdcl.ml/os-is-bad.
TideLift, Inc. Maximise the health and security of the open source powering your applications. 2023. URL: https://tidelift.com.
GitHub, Inc. Invest in the software that powers your world. 2023. URL: sponsors.
Open Collective. Raise and spend money with full transparency. 2023. URL: https://opencollective.com.
NumFOCUS, Inc. A nonprofit supporting open code for better science. 2023. URL: https://numfocus.org.
Cameron R. Wolfe. The history of open-source LLMs: better base models (part two). 2023. URL: https://cameronrwolfe.substack.com/i/135439692/better-data-better-performance.
Adrian Tam. What are zero-shot prompting and few-shot prompting. 2023. URL: https://machinelearningmastery.com/what-are-zero-shot-prompting-and-few-shot-prompting/.
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge. 2018. arXiv:1803.05457.
Het Trivedi and Casper da Costa-Luis. Evaluating open-source large language models. 2023. URL: https://dev.premai.io/blog/evaluating-open-source-llms/#picking-the-rightllm.
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: can a machine really finish your sentence? 2019. arXiv:1905.07830.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. 2021. arXiv:2009.03300.
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: measuring how models mimic human falsehoods. 2022. arXiv:2109.07958.
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, and others. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. 2023. arXiv:2306.05685.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, and others. Evaluating large language models trained on code. 2021. arXiv:2107.03374.
Gyan Prakash Tripathi. How to evaluate a large language model (LLM)? 2023. URL: https://www.analyticsvidhya.com/blog/2023/05/how-to-evaluate-a-large-language-model-llm.
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, and others. Beyond the imitation game: quantifying and extrapolating the capabilities of language models. 2023. arXiv:2206.04615.
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: a multi-task benchmark and analysis platform for natural language understanding. 2019. arXiv:1804.07461.
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: learning feature matching with graph neural networks. 2020. arXiv:1911.11763.
Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial NLI: a new benchmark for natural language understanding. 2020. arXiv:1910.14599.
Siva Reddy, Danqi Chen, and Christopher D. Manning. CoQA: a conversational question answering challenge. 2019. arXiv:1808.07042.
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: word prediction requiring a broad discourse context. 2016. arXiv:1606.06031.
Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. LogiQA: a challenge dataset for machine reading comprehension with logical reasoning. 2020. arXiv:2007.08124.
Adina Williams, Nikita Nangia, and Samuel R. Bowman. A broad-coverage challenge corpus for sentence understanding through inference. 2018. arXiv:1704.05426.
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. 2016. arXiv:1606.05250.
Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. AlpacaFarm: a simulation framework for methods that learn from human feedback. 2023. arXiv:2305.14387.
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. MTEB: massive text embedding benchmark. 2023. arXiv:2210.07316.
Chip Huyen. Building LLM applications for production. 2023. URL: https://huyenchip.com/2023/04/11/llm-engineering.html.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: a method for automatic evaluation of machine translation. In 40th Assoc. Computational Linguistics, 311–318. 2002.
Chin-Yew Lin. ROUGE: a package for automatic evaluation of summaries. In Text Summarisation Branches Out, 74–81. Barcelona, Spain, 2004. Assoc. Computational Linguistics. URL: https://aclanthology.org/W04-1013.
Satanjeev Banerjee and Alon Lavie. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments. In ACL Intrinsic & Extrinsic Eval. Measures Mach. Translat. Sum., 65–72. Ann Arbor, Michigan, 2005. Assoc. Computational Linguistics. URL: https://aclanthology.org/W05-0909.
Catherine Stevens, Nicole Lees, Julie Vonwiller, and Denis Burnham. On-line experimental methods to evaluate text-to-speech (TTS) synthesis: effects of voice gender and signal quality on intelligibility, naturalness and preference. Computer speech & language, 19(2):129–146, 2005.
Mohamed Benzeghiba, Renato De Mori, Olivier Deroo, Stephane Dupont, Teodora Erbes, Denis Jouvet, Luciano Fissore, Pietro Laface, and others. Automatic speech recognition and speech variability: a review. Speech communication, 49(10-11):763–786, 2007.
Keith Ito and Linda Johnson. The LJ Speech dataset. 2017. URL: https://keithito.com/LJ-Speech-Dataset.
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. MLS: a large-scale multilingual dataset for speech research. In Interspeech 2020. ISCA, oct 2020. doi:10.21437/interspeech.2020-2826.
Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, and others. Common Voice: a massively-multilingual speech corpus. 2020. arXiv:1912.06670.
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J. Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. LibriTTS: a corpus derived from librispeech for text-to-speech. 2019. arXiv:1904.02882.
Alexis Conneau, Min Ma, Simran Khanuja, Yu Zhang, Vera Axelrod, Siddharth Dalmia, Jason Riesa, Clara Rivera, and Ankur Bapna. FLEURS: few-shot learning evaluation of universal representations of speech. In 2022 IEEE Spoken Language Technology Workshop (SLT), 798–805. IEEE, 2023.
Sanchit Gandhi, Patrick von Platen, and Alexander M. Rush. ESB: a benchmark for multi-domain end-to-end speech recognition. 2022. arXiv:2210.13352.
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, and others. Microsoft COCO: common objects in context. 2015. arXiv:1405.0312.
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: a large-scale hierarchical image database. In IEEE CVPR, 248–255. IEEE, 2009.
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In IEEE CVPR, 633–641. 2017.
Zijie J. Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. DiffusionDB: a large-scale prompt gallery dataset for text-to-image generative models. 2023. arXiv:2210.14896.
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: a dataset of 101 human actions classes from videos in the wild. 2012. arXiv:1212.0402.
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. MSR-VTT: a large video description dataset for bridging video and language. In IEEE CVPR, 5288–5296. 2016.
Christopher D Manning. Human language understanding & reasoning. Daedalus, 151(2):127–138, 2022.
David J Hand. Classifier technology and the illusion of progress. Statistical Science, 2006.
Ehud Reiter. Evaluating chatGPT. 2023. URL: https://ehudreiter.com/2023/04/04/evaluating-chatgpt.
Cynthia Rudin, Chaofan Chen, Zhi Chen, Haiyang Huang, Lesia Semenova, and Chudi Zhong. Interpretable machine learning: fundamental principles and 10 grand challenges. 2021. arXiv:2103.11251.
Skanda Vivek. How do you evaluate large language model apps — when 99% is just not good enough? 2023. URL: https://skandavivek.substack.com/p/how-do-you-evaluate-large-language.
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, and others. A survey of large language models. 2023. arXiv:2303.18223.
Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: unsupervised pre-training for speech recognition. 2019. arXiv:1904.05862.
Nathan Lambert, Louis Castricato, Leandro von Werra, and Alex Havrilla. Illustrating reinforcement learning from human feedback (RLHF). 2022. URL: https://huggingface.co/blog/rlhf.
Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, and others. GPT-NeoX 20B: an open-source autoregressive language model. 2022. arXiv:2204.06745.
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, and others. OPT: open pre-trained transformer language models. 2022. arXiv:2205.01068.
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: enhanced transformer with rotary position embedding. 2022. arXiv:2104.09864.
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, and others. The Pile: an 800gb dataset of diverse text for language modeling. 2020. arXiv:2101.00027.
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. 2022. arXiv:2112.10752.
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, and others. Photorealistic text-to-image diffusion models with deep language understanding. 2022. arXiv:2205.11487.
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, and others. Learning transferable visual models from natural language supervision. 2021. arXiv:2103.00020.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, and others. LLaMA: open and efficient foundation language models. 2023. arXiv:2302.13971.
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, and others. Training compute-optimal large language models. 2022. arXiv:2203.15556.
Biao Zhang and Rico Sennrich. Root mean square layer normalisation. 2019. arXiv:1910.07467.
Noam Shazeer. GLU variants improve transformer. 2020. arXiv:2002.05202.
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: aligning language models with self-generated instructions. 2023. arXiv:2212.10560.
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. 2016. arXiv:1604.06174.
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: fast and memory-efficient exact attention with IO-awareness. 2022. arXiv:2205.14135.
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, and others. LLaMA-Adapter: efficient fine-tuning of language models with zero-init attention. 2023. arXiv:2303.16199.
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, and others. OpenAssistant conversations – democratizing large language model alignment. 2023. arXiv:2304.07327.
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. WizardLM: empowering large language models to follow complex instructions. 2023. arXiv:2304.12244.
Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: attention with linear biases enables input length extrapolation. 2022. arXiv:2108.12409.
Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The refinedweb dataset for falcon LLM: outperforming curated corpora with web data, and web data only. 2023. arXiv:2306.01116.
Noam Shazeer. Fast transformer decoding: one write-head is all you need. 2019. arXiv:1911.02150.
Shashank Sonkar and Richard G. Baraniuk. Investigating the role of feed-forward networks in transformers using parallel attention and feed-forward net design. 2023. arXiv:2305.13297.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, and others. LLaMA 2: open foundation and fine-tuned chat models. 2023. arXiv:2307.09288.
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. GQA: training generalised multi-query transformer models from multi-head checkpoints. 2023. arXiv:2305.13245.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, and others. PaLM: scaling language modeling with pathways. 2022. arXiv:2204.02311.
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: improving latent diffusion models for high-resolution image synthesis. 2023. arXiv:2307.01952.
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, and others. WizardCoder: empowering code large language models with evol-instruct. 2023. arXiv:2306.08568.
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, and others. Code LLaMA: open foundation models for code. 2023. arXiv:2308.12950.
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normalization for transformers. 2020. arXiv:2010.04245.
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, and others. Scaling vision transformers to 22 billion parameters. 2023. arXiv:2302.05442.
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, and others. Flamingo: a visual language model for few-shot learning. 2022. arXiv:2204.14198.
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. 2019. arXiv:1904.10509.
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: the long-document transformer. 2020. arXiv:2004.05150.
Will Knight. The myth of open source AI. 2023. URL: https://www.wired.com/story/the-myth-of-open-source-ai.
The reversal curse: LLMs trained on "A is B" fail to learn "B is A". 2023. URL: https://twitter.com/OwainEvans_UK/status/1705285631520407821.
Eric Hartford. Uncensored models. 2023. URL: https://erichartford.com/uncensored-models.
Zac Amos. What is FraudGPT? 2023. URL: https://hackernoon.com/what-is-fraudgpt.
Rakesh Krishnan. FraudGPT: the villain avatar of ChatGPT. 2023. URL: https://netenrich.com/blog/fraudgpt-the-villain-avatar-of-chatgpt.
Daniel Kelley. WormGPT – the generative AI tool cybercriminals are using to launch business email compromise attacks. 2023. URL: https://slashnext.com/blog/wormgpt-the-generative-ai-tool-cybercriminals-are-using-to-launch-business-email-compromise-attacks.
Mandy. What is PoisonGPT and how does it work? 2023. URL: https://aitoolmall.com/news/what-is-poisongpt.
Daniel Huynh and Jade Hardouin. PoisonGPT: how we hid a lobotomised LLM on Hugging Face to spread fake news. 2023. URL: https://blog.mithrilsecurity.io/poisongpt-how-we-hid-a-lobotomized-llm-on-hugging-face-to-spread-fake-news.
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar. ToxiGen: a large-scale machine-generated dataset for adversarial and implicit hate speech detection. 2022. arXiv:2203.09509.
Roger Montti. New open source LLM with zero guardrails rivals google's PaLM 2. 2023. URL: https://www.searchenginejournal.com/new-open-source-llm-with-zero-guardrails-rivals-google-palm-2/496212.
Bill Toulas. Cybercriminals train AI chatbots for phishing, malware attacks. 2023. URL: https://www.bleepingcomputer.com/news/security/cybercriminals-train-ai-chatbots-for-phishing-malware-attacks.
Separate-Still3770. PoisonGPT: example of poisoning LLM supply chain to hide a lobotomized LLM on Hugging Face to spread fake news. 2023. URL: https://www.reddit.com/r/MachineLearning/comments/14v2zvg/p_poisongpt_example_of_poisoning_llm_supply_chain.
Ruixiang Tang, Yu-Neng Chuang, and Xia Hu. The science of detecting LLM-generated texts. 2023. arXiv:2303.07205.
Anna Glazkova, Maksim Glazkov, and Timofey Trifonov. g2tmn at Constraint@AAAI2021: exploiting CT-BERT and ensembling learning for COVID-19 fake news detection. In Combating Online Hostile Posts in Regional Languages during Emergency Situation, pages 116–127. Springer International Publishing, 2021. doi:10.1007/978-3-030-73696-5_12.
Jessica Yao. Why you (probably) don't need to fine-tune an LLM. 2023. URL: http://www.tidepool.so/2023/08/17/why-you-probably-dont-need-to-fine-tune-an-llm.
Justin Gage. The beginner's guide to fine-tuning stable diffusion. 2023. URL: https://octoml.ai/blog/the-beginners-guide-to-fine-tuning-stable-diffusion.
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. BloombergGPT: a large language model for finance. 2023. arXiv:2303.17564.
Wouter Van Heeswijk. Is "small data" the next big thing in data science? Towards Data Science, 2022. URL: https://towardsdatascience.com/is-small-data-the-next-big-thing-in-data-science-9acc7f24907f.
Purvish Jajal, Wenxin Jiang, Arav Tewari, Joseph Woo, Yung-Hsiang Lu, George K. Thiruvathukal, and James C. Davis. Analysis of failures and risks in deep learning model converters: a case study in the ONNX ecosystem. 2023. arXiv:2303.17708.
Valohai Inc. Pros and cons of open-source and managed MLOps platforms. 2022. URL: https://valohai.com/managed-vs-open-source-mlops.
Nvidia Corp. Supercharging AI video and AI inference performance with NVIDIA L4 GPUs. 2023. URL: https://developer.nvidia.com/blog/supercharging-ai-video-and-ai-inference-performance-with-nvidia-l4-gpus.
Bharat Venkitesh. Cohere boosts inference speed with NVIDIA triton inference server. 2022. URL: https://txt.cohere.com/nvidia-boosts-inference-speed-with-cohere.
Aman. Why GPT-3.5 is (mostly) cheaper than LLaMA-2. 2023. URL: https://cursor.sh/blog/llama-inference.
Prashanth Rao. Vector databases: not all indexes are created equal. 2023. URL: https://thedataquarry.com/posts/vector-db-3.
David Gutsch. Vector databases: understanding the algorithm (part 3). 2023. URL: https://medium.com/@david.gutsch0/vector-databases-understanding-the-algorithm-part-3-bc7a8926f27c.
Inc Pinecone Systems. Product quantisation: compressing high-dimensional vectors by 97%. 2023. URL: https://www.pinecone.io/learn/series/faiss/product-quantization.
Marcel Deer. How much data in the world is unstructured? 2023. URL: https://www.unleash.so/a/answers/database-management/how-much-data-in-the-world-is-unstructured.
NVIDIA Corporation. Your GPU compute capability. 2023. URL: https://developer.nvidia.com/cuda-gpus.