Vector Databases#
Work in Progress
This chapter is still being written & reviewed. Please do post links & discussion in the comments below, or open a pull request!
Some ideas:
short sections for each of the rows from the table below
Vector databases have exploded in popularity in the past year due to generative AI, but the concept of vector embedding has existed for many years. When performing image classification, the “features” extracted by a neural network are the “vector embeddings”. These vector embeddings contain distilled (“compressed”) information about the image. For text-based models, vector embeddings capture the relationship between words, allowing models to understand language. Embeddings can be stored in databases for later lookup/retrieval.
Vector Database |
Open Source |
Sharding |
Supported Distance Metrics |
Supported Indices |
|---|---|---|---|---|
🟢 Yes |
🟢 Yes |
cosine, dot, L2 squared, hamming, manhattan |
HNSW, HNSW-PQ |
|
🟢 Yes |
🟢 Yes |
cosine, dot, euclidean |
HNSW |
|
🟢 Yes |
🟢 Yes |
cosine, dot, euclidean, jaccard, hamming |
HNSW, FLAT, IVF-FLAT, IVF-PQ |
|
🟢 Yes |
🟢 Yes |
cosine, inner product, L2 |
HNSW, FLAT |
|
🟢 Yes |
🔴 No |
cosine, inner product, L2 |
HNSW |
|
🔴 No |
🟢 Yes |
cosine, dot, euclidean |
HNSW, FLAT, LSH, PQ |
|
🟢 Yes |
🟢 Yes |
cosine, inner product, L2, taxicab |
IVFFLAT, HNSW |
LLM Embeddings#
Large language models are trained on a massive text corpus such as Wikipedia. As the model processes this text, it learns representations for words based on their context.
As the model learns from the data, it represents each word as a high-dimensional vector, usually with hundreds or thousands of dimensions. The values in the vector encode the semantic meaning of the word.
After training on a large corpora of text, words with similar meanings end up closer together in the vector space.
The resulting word vectors capture semantic relationships between words, which allows the model to generalise better on language tasks. These pre-trained embeddings are then used to initialise the first layer of large language models like BERT.
To summarise, by training the model on a large set of text data you end up with a model specifically designed to capture the relationship between words, i.e., vector embeddings.
Turning text into embeddings#

Fig. 64 Vector Embeddings#
Let’s take the sentence from the image above as an example: “I want to adopt a puppy”
Each word in the sentence is mapped to its corresponding vector representation using the pre-trained word embeddings. For example, the word “adopt” may map to a 300-dimensional vector, “puppy” to another 300-dim vector, and so on.
The sequence of word vectors is then passed through the neural network architecture of the language model.
As the word vectors pass through the model, they interact with each other and get transformed by mathematical functions. This allows the model to interpret the meaning of the full sequence.
The output of the model is a new vector that represents the embedding for the full input sentence. This sentence embedding encodes the semantic meaning of the entire sequence of words.
Many closed-source models like text-embedding-ada-002 from OpenAI and the embeddings model from Cohere allow developers to convert raw text into vector embeddings. It’s important to note that the models used to generate vector embeddings are NOT the same models used for text generation.
Embeddings vs Text Generation
For NLP, embeddings are trained on a language modeling objective. This means they are trained to predict surrounding words/context, not to generate text.
Embedding models are encoder-only models without decoders. They output an embedding, not generated text.
Generation models like GPT-2/3 have a decoder component trained explicitly for text generation.
Vector Databases#
Vector databases allow for efficient storage & search of vector embeddings.
Calculating distance between vectors#
Most vector databases support 3 main distance metrics:
Euclidean distance: the straight line distance between two points in the vector space
Cosine similarity: the cosine of the angle between two vectors – the larger the cosine, the closer the vectors
Dot product: product of cosine similarity and the magnitudes (lengths) of the vectors – the larger the dot product, the closer the vectors
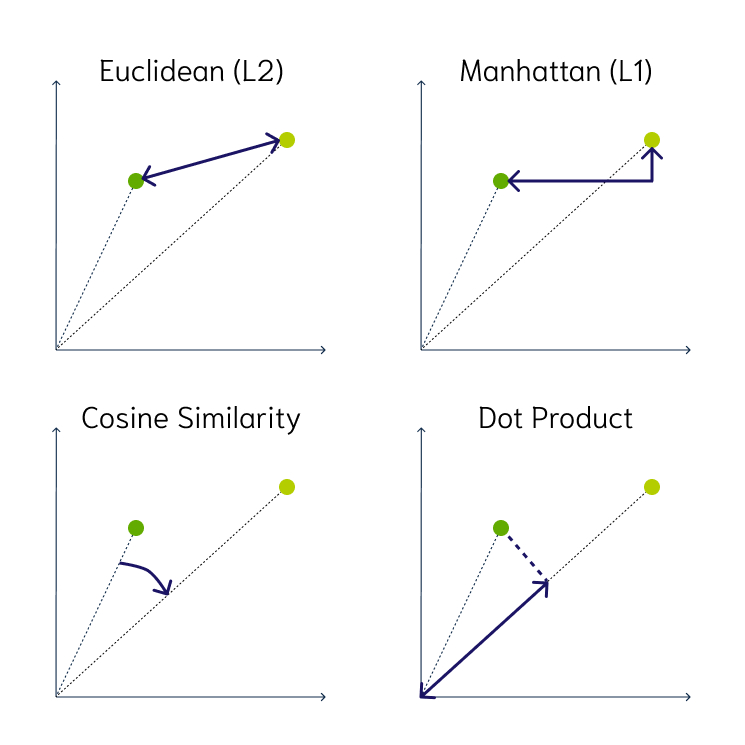
Fig. 65 Vector Distance Metrics#
Vector Indexing#
Even though vector databases can contain metadata in the form of JSON objects, the primary type of data is vectors. Unlike relational databases or NoSQL databases, vector databases optimise operations to make reading and writing vectors as fast as possible.
With vector databases, there are two different concepts of indexing and search algorithms, both of which contribute to the overall performance. In many situations, choosing a vector index involves a trade-off between accuracy (precision/recall) and speed/throughput [148]. There are two primary factors that help organise an index:
The underlying data structure
Level of compression
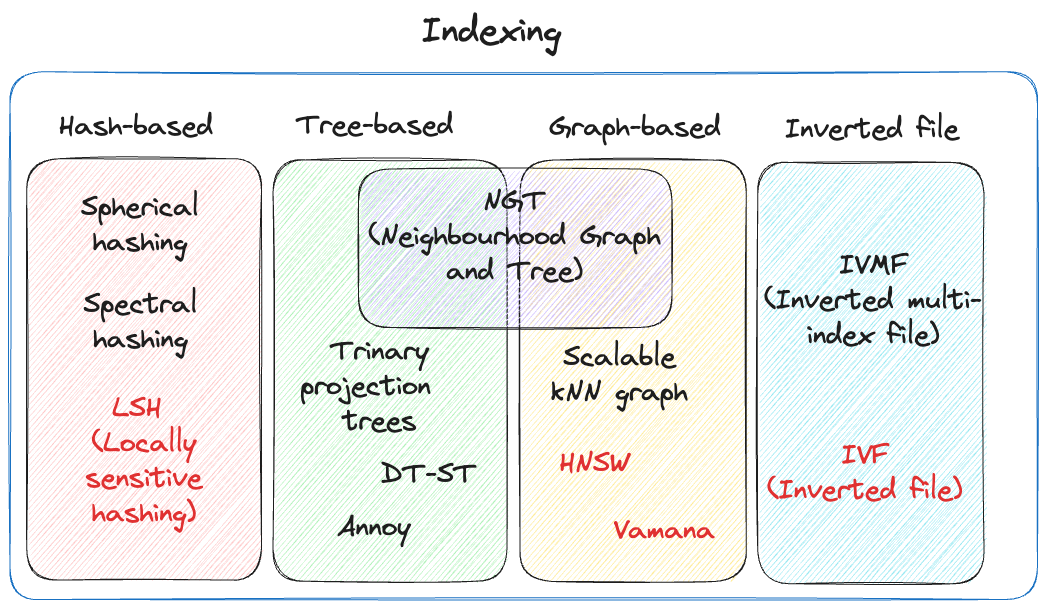
Fig. 66 Vector Indexing#
Hash-based Indexing#
Locality-Sensitive Hashing (LSH) used hash functions to bucket similar vectors into a hash table. The query vectors are also hashed using the same hash function and it is compared with the other vectors already present in the table.
This method is much faster than doing an exhaustive search across the entire dataset because there are fewer vectors in each hash table than in the whole vector space. While this technique is quite fast, the downside is that it is not very accurate. LSH is an approximate method, so a better hash function will result in a better approximation, but the result will not be the exact answer.
Tree-based Indexing#
Tree-based indexing allows for fast searches by using a data structure such as a binary tree. The tree gets created in a way that similar vectors are grouped in the same subtree. spotify/annoy (Approximate Nearest Neighbour Oh Yeah) uses a forest of binary trees to perform approximate nearest neighbors search. Annoy performs well with high-dimension data where doing an exact nearest neighbors search can be expensive. The downside of using this method is that it can take a significant amount of time to build the index. Whenever a new data point is received, the indices cannot be restructured on the fly. The entire index has to be rebuilt from scratch.
Graph-based Indexing#
Similar to tree-based indexing, graph-based indexing groups similar data points by connecting them with an edge. Graph-based indexing is useful when trying to search for vectors in a high-dimensional space. HNSW (Hierarchical Navigable Small World) is a popular graph based index that is designed to provide a balance between search speed and accuracy.

HNSW creates a layered graph with the topmost layer containing the fewest points and the bottom layer containing the most points [149]. When an input query comes in, the topmost layer is searched via ANN. The graph is traversed downward layer by layer. At each layer, the ANN algorithm is run to find the closest point to the input query. Once the bottom layer is hit, the nearest point to the input query is returned.
Graph-based indexing is very efficient because it allows one to search through a high-dimensional space by narrowing down the location at each layer. However, re-indexing can be challenging because the entire graph may need to be recreated [149].
Inverted File Index#
IVF narrows the search space by partitioning the dataset and creating a centroid(random point) for each partition. The centroids get updated via the K-Means algorithm. Once the index is populated, the ANN algorithm finds the nearest centroid to the input query and only searches through that partition.
Although IVF is efficient at searching for similar points once the index is created, the process of creating the partitions and centroids can be quite slow.
Vector Compression#
Vectors can take up a lot of memory in terms of storage. High dimensional data adds to this problem which can end up making vector search slow and difficult to manage. To tackle this issue, compression is used to reduce the overall footprint of the vector while still retaining the core structure of the data.
There are two kinds of compression techniques:
Flat
Product Quantisation (PQ)
Flat compression does not modify the vectors and keeps the original structure. When an input query comes in a kNN search is done to find the exact match between the input vector and the vectors present in the vector database. This leads to a high level of accuracy, but it comes at the cost of speed. The search time increases linearly as the size of the dataset grows. When dealing with larger datasets, flat will likely yield poor results in terms of latency.
On the other hand, product quantisation reduces the memory footprint of the original vectors by decreasing the number of dimensions. It splits the original vector into chunks and gives each chunk an id. These chunks are created in a way that the distance between them can be calculated efficiently.
Product Quantisation works well for large datasets and high-dimension spaces. It can greatly speed up the nearest neighbour search and reduce the overall memory footprint by ~97%. The downside of using this compression technique is that it can lead to lower accuracy and recall [150].
Searching Algorithms#
Vector indexing is more about selecting the underlying data structure to store the vectors. Vector searching is about picking the algorithm used to search on that data structure.
A basic algorithm used for vector search is kNN (K-Nearest Neighbors). kNN works by calculating the distance between the input vector and all of the other vectors inside the vector database. This algorithm does not scale well as the number of vectors increases, because as the number of vectors increases so does the search time.
There is a more efficient search algorithm commonly used by vector databases called ANN(Approximate Nearest Neighbors). ANN works by pre-computing the distance between the vectors and storing them in a way so that similar vectors are placed closer to each other.
By grouping or clustering similar vectors, the algorithm can quickly narrow down the search space without wandering further away from the input query.
Popular Use-Cases#
A common use case for vector databases is search. Whether it’s searching for similar text or images, this tool can efficiently find the data you are looking for.
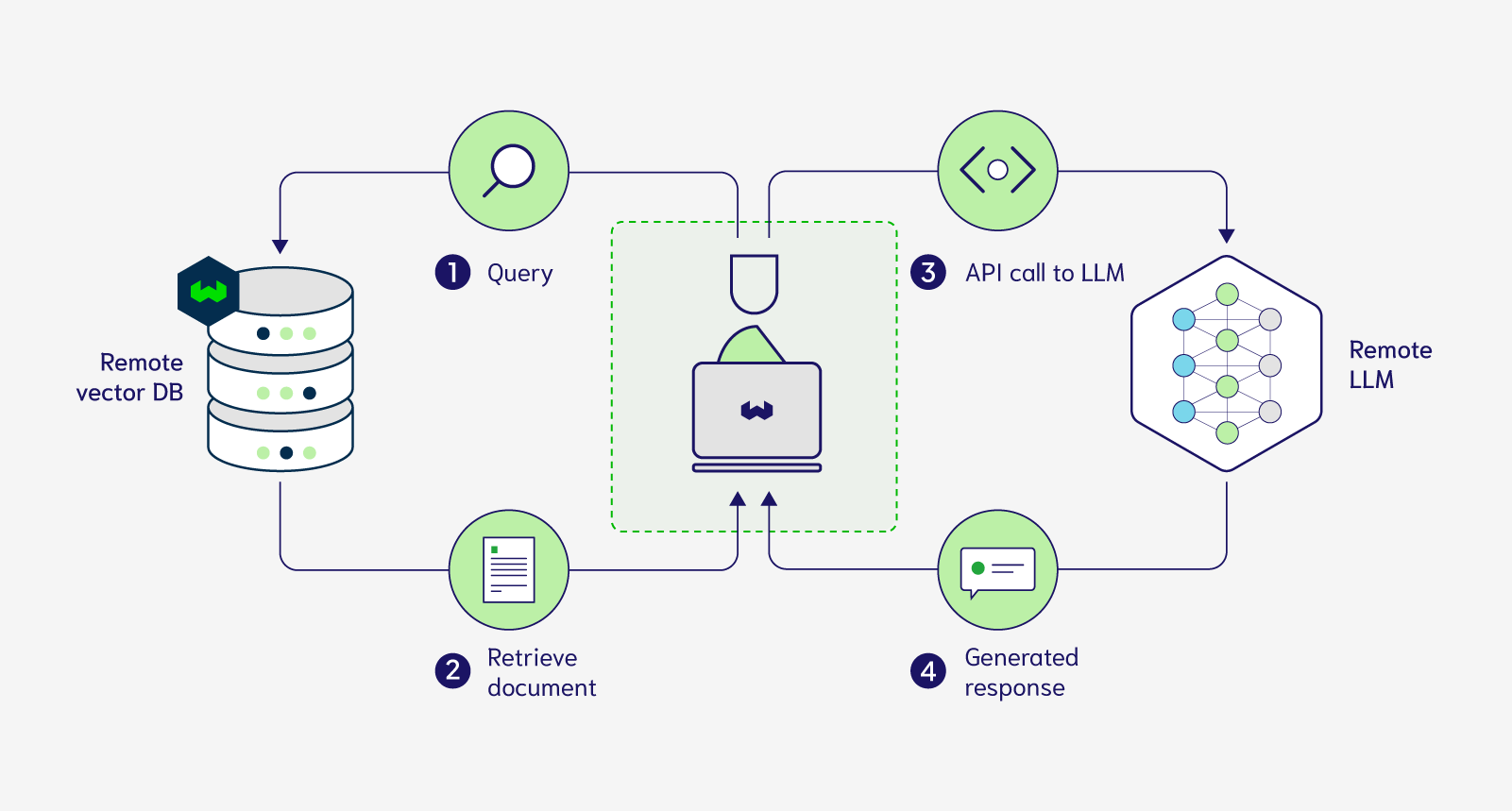
In the context of LLMs, vector databases are often used to retrieve information from the user’s query to use in the prompt of the LLM. Vector databases can serve as long-term memory for LLMs so that only the bits that are relevant to the input query are injected into the prompt.
Another use case is recommendation engines. Recommendations by nature, are about finding similar products. A relational or NoSQL database would not work well in this case, because an exact match is not needed. Vector databases have been used for various recommendations from movies to e-commerce products.
Limitations#
While there are many advantages to using vector databases in certain applications, there are also a few issues to be aware of:
Data structure
Vector databases are optimised to work with only vector data. The underlying data structures may not be suitable for working with tabular or JSON data.
For this reason, vector databases should not be used as a replacement for other types of databases as they lack many of the features such as being ACID-compliant.
Debugging difficulty
To humans a vector looks like a random list of numbers. These numbers don’t make any sense to us, so it becomes difficult to interpret what this vector represents.
Unlike a relational database where we can read the data in each column, we cannot simply read the vector. This makes vector data difficult to debug, as we have to rely on algorithms and metrics to make sense of the data.
Indexing issues
The way a vector database is indexed is crucial to its search performance.
However, due to the way some indices are designed it can be quite challenging to modify or delete data. For some indices, the entire underlying data structure needs to be re-formatted when data changes are made.
Future#
Vector databases provide a unique solution to problems that are not sufficiently addressed by relational or NoSQL databases
Instead of competing directly against prior databases, it has carved out its own category in the tech stack
Advancements in indexing and searching algorithms will make vector databases faster and cheaper
80–90% of the data daily generated on the internet is unstructured [151]. Most of it is in the form of text, images, and video. Vector databases can help extract value from unstructured data, whether is improving LLM accuracy, image similarity, or product recommendations.
For the foreseeable future, vector databases are here to stay. It seems unlikely that they will replace or get replaced by traditional databases as they both serve different purposes. This technology will eventually become a mainstream component in the AI tech stack.
Feedback
Missing something important? Let us know in the comments below, or open a pull request!